Publications
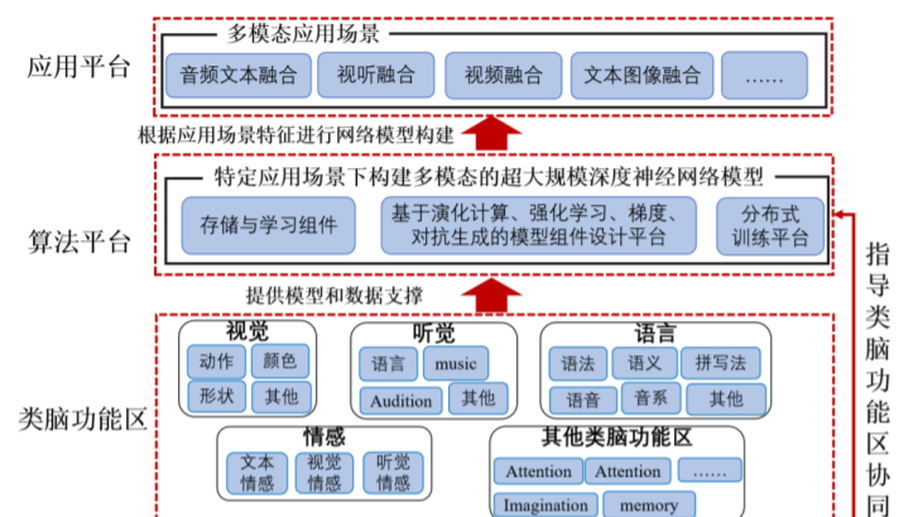
Brain-Inspired Large-Scale Deep Neural Network System.
Large-scale deep neural networks (DNNs) exhibit powerful end-to-end representation and infinite approximation of nonlinear functions, showing excellent performance in several fields and becoming an important development direction. For example, the natural language processing model GPT, after years of development, now has 175 billion network parameters and achieves state-of-the-art performance on several NLP benchmarks. However, according to the existing deep neural network organization, the current large-scale network is difficult to reach the scale of human brain biological neural network connection. At the same time, the existing large-scale DNNs do not perform well in multi-channel collaborative processing, knowledge storage, and reasoning. In this paper, we propose a brain-inspired large-scale DNN model, which is inspired by the division and the functional mechanism of brain regions and built modularly by the functional of the brain, integrates a large amount of existing data and pre-trained models, and proposes the corresponding learning algorithm by the functional mechanism of the brain. The DNN model implements a pathway to automatically build a DNN as an output using the scene as an input. Simultaneously, it should not only learn the correlation between input and output but also needs to have the multi-channel collaborative processing capability to improve the correlation quality, thereby realizing knowledge storage and reasoning ability, which could be treated as a way toward general artificial intelligence. The whole model and all data sets and brain-inspired functional areas are managed by a database system which is equipped with the distributed training algorithms to support the efficient training of the large-scale DNN on computing clusters. In this paper, we propose a novel idea to implement general artificial intelligence. Eventually, the large-scale model is validated on several different modal tasks.
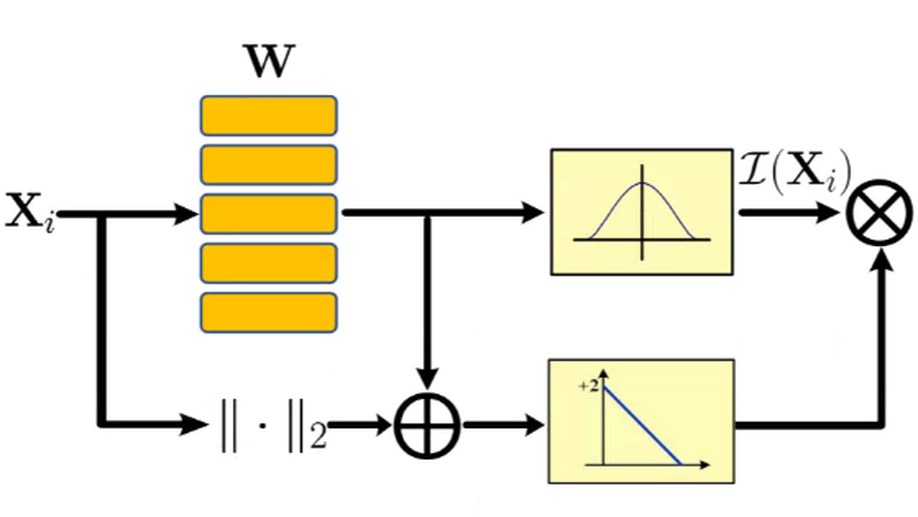
XAI Beyond Classification: Interpretable Neural Clustering.
In this paper, we study two challenging problems in explainable AI (XAI) and data clustering. The first is how to directly design a neural network with inherent interpretability, rather than giving post-hoc explanations of a black-box model. The second is implementing discrete k-means with a differentiable neural network that embraces the advantages of parallel computing, online clustering, and clustering-favorable representation learning. To address these two challenges, we design a novel neural network, which is a differentiable reformulation of the vanilla k-means, called inTerpretable nEuraL cLustering (TELL). Our contributions are threefold. First, to the best of our knowledge, most existing XAI works focus on supervised learning paradigms. This work is one of the few XAI studies on unsupervised learning, in particular, data clustering. Second, TELL is an interpretable, or the so-called intrinsically explainable and transparent model. In contrast, most existing XAI studies resort to various means for understanding a black-box model with post-hoc explanations. Third, from the view of data clustering, TELL possesses many properties highly desired by k-means, including but not limited to online clustering, plug-and-play module, parallel computing, and provable convergence. Extensive experiments show that our method achieves superior performance comparing with 14 clustering approaches on three challenging data sets. The source code could be accessed at www.pengxi.me.
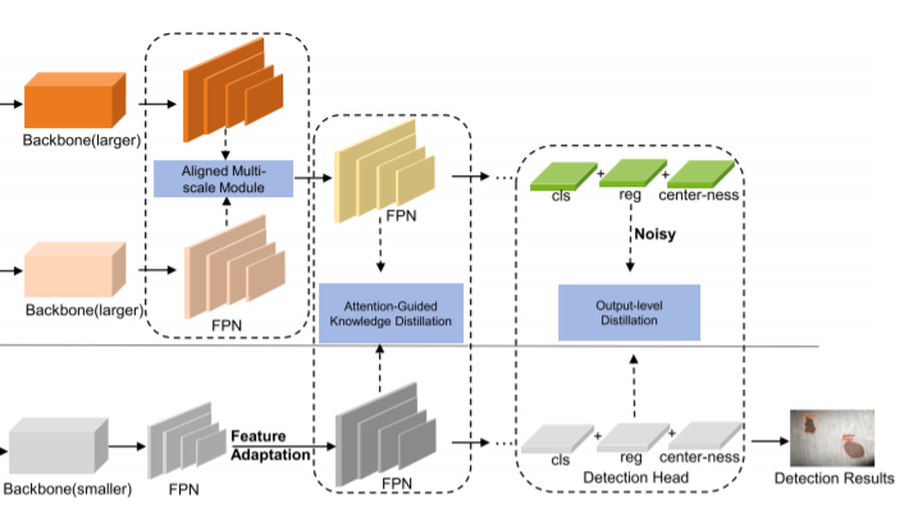
Knowledge Distillation Method for Surface Defect Detection.
In this paper, we propose a multi-scale attention mechanism-guided knowledge distillation method for surface defect detection. Enables a lighter student model to mimic the complex teacher model through the use of knowledge distillation techniques, the proposed method improves the defect detection accuracy and maintains high real-time performance, simultaneously. Specifically, we first present a multi-scale fusion-based teacher network. Owing to the fusion of two resolution scales features, the teacher network can keep high compatibility with the low-resolution student network during knowledge distillation, so as to better direct the student model. Then, in the process of knowledge distillation, attentional mechanisms were introduced with the aim of enabling the student network to more effectively mimic the foreground attention map and features of the teacher network. Finally, in order to address the imbalance of foreground and background in defect detection, we introduce a class-weighted cross entropy loss. Experiments conducted on three benchmark datasets proved the validity and efficiency of the proposed method in surface defect detection.
ArcText: A Unified Text Approach to Describing Convolutional Neural Network Architectures.
The superiority of Convolutional Neural Networks (CNNs) largely relies on their architectures that are usually manually crafted with extensive human expertise. Unfortunately, such kind of domain knowledge is not necessarily owned by every interested user. Data mining on existing CNNs can discover useful patterns and fundamental comments from their architectures, providing researchers with strong prior knowledge to design effective CNN architectures when they have no expertise in CNNs. There are various state-of-the-art data mining algorithms at hand, while there is only rare work on mining CNN architectures. One of the main reasons is the gap between CNN architectures and data mining algorithms. Specifically, the current CNN architecture descriptions cannot be exactly vectorized to feed to an data mining algorithm. In this paper, we propose a unified approach, named ArcText, to describing CNN architectures based on text. Particularly, four different units and an ordering method have been elaborately designed in ArcText, to uniquely describe the same CNN architecture with sufficient information. Also, the resulted description can be exactly converted back to the corresponding CNN architecture. ArcText bridges the gap between CNN architectures and data mining researchers, and has the potential to be utilized to wider scenarios..
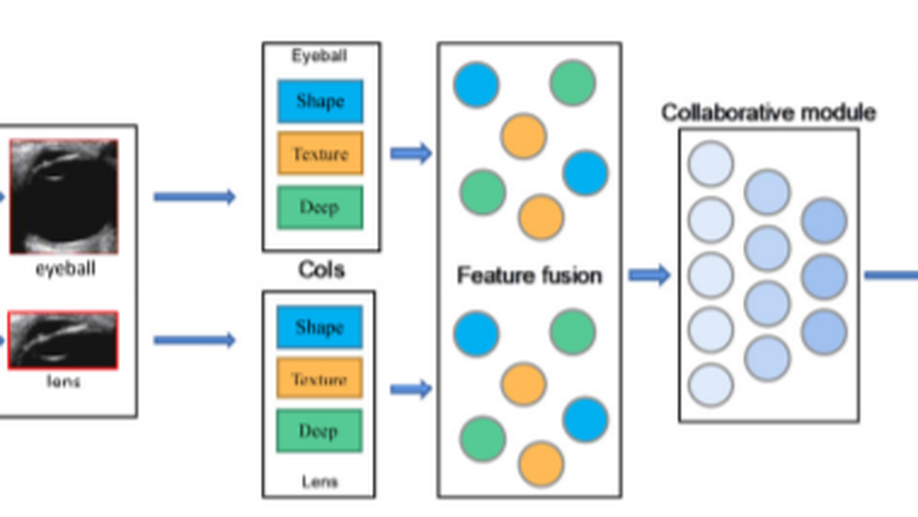
Cataract detection based on ocular B-ultrasound images by collaborative monitoring deep learning.
In this paper, we collect an ocular B-ultrasound image dataset and propose a Collaborative Monitoring Deep Learning (CMDL) method to detect cataract. In the ocular B-ultrasound images, there are often strong echoes near the posterior capsule and lens, and the fine-grained ocular B-ultrasound images are often accompanied by the characteristics of weak penetrating power, low contrast, narrow imaging range, and high noise. Thus, in the proposed CMDL method, we introduce an object detection network based on YOLO-v3 to detect the focus areas we need, so as to reduce the interference of noise and improve the cataract detection accuracy of our method. Considering that the B-ultrasound image dataset we collected is small-scale, we also design three feature extraction modules to avoid over-fitting of the deep neural networks. Among them, there are a depth features extraction module based on DenseNet-161, a shape features extractor based on Fourier descriptor, and a texture features extraction module based on gray-level co-occurrence matrix. Moreover, we also introduce the collaborative learning module to improve the generalization of the proposed model. Specifically, we first fuse the depth, shape, and texture features of the eyeball and lens, respectively. Then, the fused features of the eyeball and lens are concatenated as the input of collaborative network. Finally, the introduced classification loss with the aid of collaborative loss, which distinguishes whether the eyeball and lens belong to the same category, improves the classification accuracy in cataract detection. Experimental results on our collected dataset demonstrate the effectiveness of the proposed CMDL method.
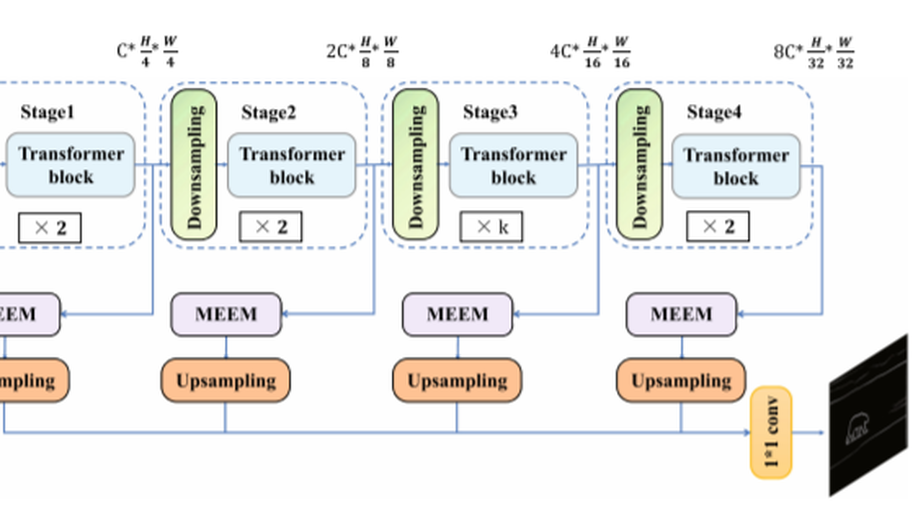
End-to-end edge detection via improved transformer model.
Recently, many efficient edge detection methods based on deep learning have emerged and made remarkable achievements. However, there are two fundamental challenges, i.e., the extraction and fusion of different scale features, as well as the sample imbalance, making the performance of edge detection need to be further promoted. In this paper, we propose an end-to-end edge detection method implemented by improved transformer model to promote edge detection by solving multi-scale fusion and sample imbalance. Specifically, based on the transformer model, we design a multi-scale edge extraction module, which utilizes pooling layer and dilated convolution with different rates and kernels, to realize multi-scale feature extraction and fusion. Moreover, we design an efficient loss function to guide the proposed method to fit the distribution of unbalanced positive and negative samples. Extensive experiments conducted on two benchmark data sets prove that the proposed method significantly outperforms state-of-the-art methods in edge detection.
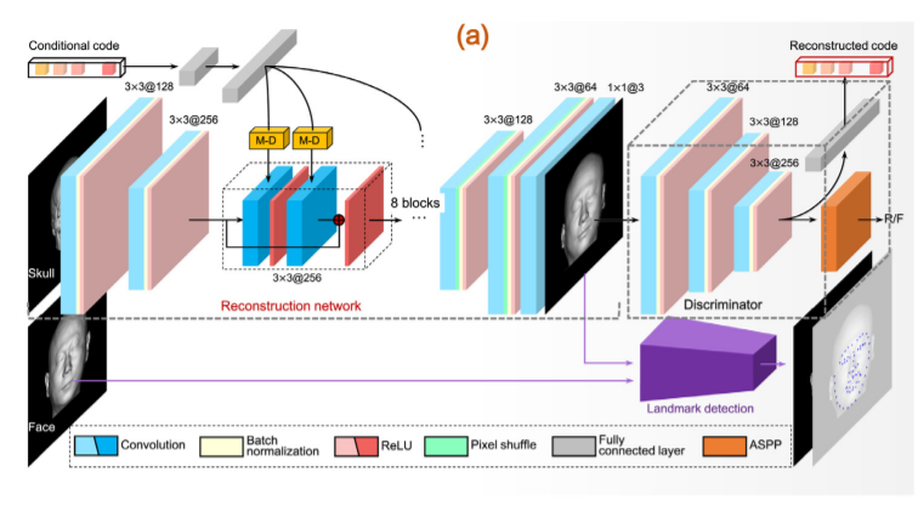
CR-GAN: Automatic craniofacial reconstruction for personal identification.
Craniofacial reconstruction is applied to identify human remains in the absence of determination data (e.g., fingerprinting, dental records, radiological materials, or DNA), by predicting the likeness of the unidentified remains based on the internal relationship between the skull and face. Conventional 3D methods are usually based on statistical models with poor capacity, which limit the description of such complex relationship. Moreover, the required high-quality data are difficult to collect. In this study, we present a novel craniofacial reconstruction paradigm that synthesize craniofacial images from 2D computed tomography scan of skull data. The key idea is to recast craniofacial reconstruction as an image translation task, with the goal of generating corresponding craniofacial images from 2D skull images. To this end, we design an automatic skull-to-face transformation system based on deep generative adversarial nets. The system was trained on 4551 paired skull-face images obtained from 1780 CT head scans of the Han Chinese population. To the best of our knowledge, this is the only database of this magnitude in the literature. Finally, to accurately evaluate the performance of the model, a face recognition task employing five existing deep learning algorithms, —FaceNet, —SphereFace, —CosFace, —ArcFace, and —MagFace, was tested on 102 reconstruction cases in a face pool composed of 1744 CT-scan face images. The experimental results demonstrate that the proposed method can be used as an effective forensic tool.
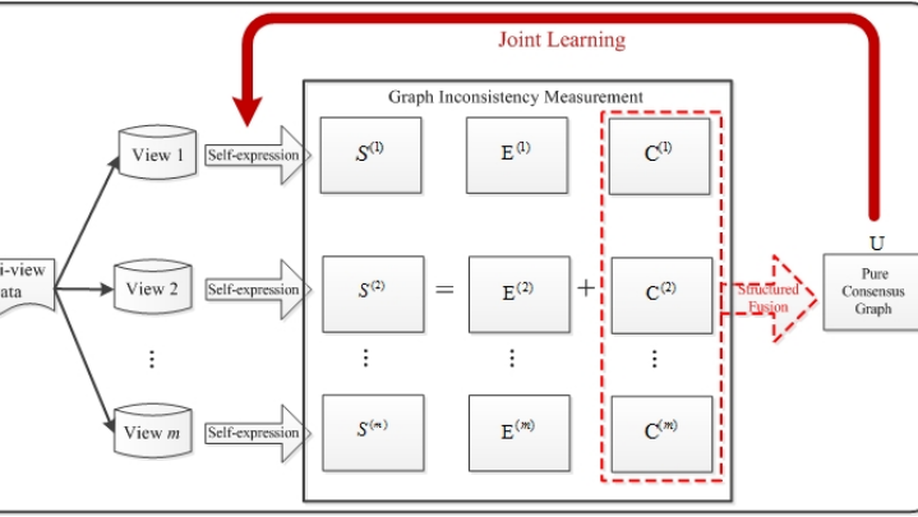
CDD: Multi-view Subspace Clustering via Cross-view Diversity Detection.
The goal of multi-view subspace clustering is to explore a common latent space where the multi-view data points lying on. Myriads of subspace learning algorithms have been investigated to boost the performance of multi-view clustering, but seldom exploiting both the multi-view consistency and multi-view diversity, let alone taking them into consideration simultaneously. To do so, we lodge a novel multi-view subspace clustering via cross-view diversity detection (CDD). CDD is able to exploit these two complementary criteria seamlessly into a holistic design of clustering algorithms. With the consistent part and diverse part being detected, a pure graph can be derived for each view. The consistent pure parts of different views are further fused to a consensus structured graph with exactly k connected components where k is the number of clusters. Thus we can directly obtain the final clustering result without any postprocessing as each connected component precisely corresponds to an individual cluster. We model the above concerns into a unified optimization framework. Our empirical studies validate that the proposed model outperforms several other state-of-the-art methods.
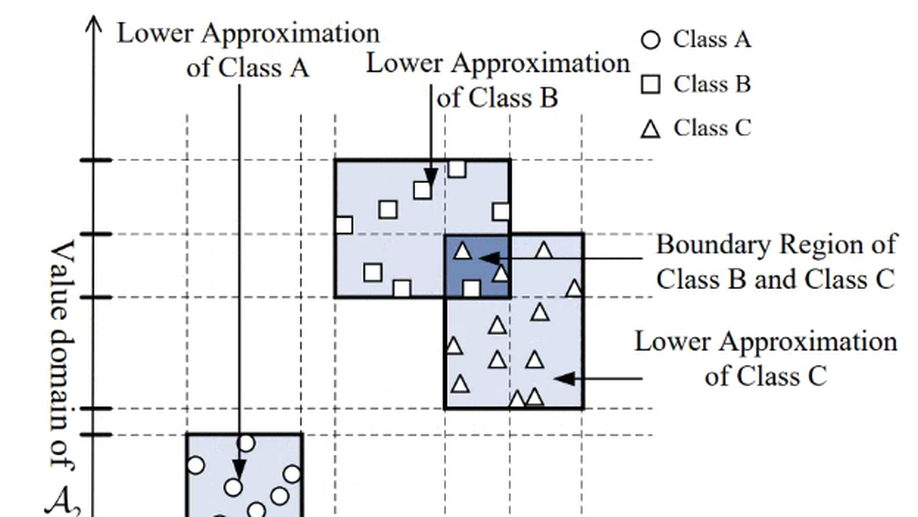
Spark Rough Hypercuboid Approach for Scalable Feature Selection.
Feature selection refers to choose an optimal non-redundant feature subset with minimal degradation of learning performance and maximal avoidance of data overfitting. The appearance of large data explosion leads to the sequential execution of algorithms are extremely time-consuming, which necessitates the scalable parallelization of algorithms by efficiently exploiting the distributed computational capabilities. In this paper, we present parallel feature selection algorithms underpinned by a rough hypercuboid approach in order to scale for the growing data volumes. Metrics in terms of rough hypercuboid are highly suitable to parallel distributed processing, and fits well with the Apache Spark cluster computing paradigm. Two data parallelism strategies, namely, vertical partitioning and horizontal partitioning, are implemented respectively to decompose the data into concurrent iterative computing streams. Experimental results on representative datasets show that our algorithms significantly faster than its original sequential counterpart while guaranteeing the quality of the results. Furthermore, the proposed algorithms are perfectly capable of exploiting the distributed-memory clusters to accomplish the computation task that fails on a single node due to the memory constraints. Parallel scalability and extensibility analysis have confirmed that our parallelization extends well to process massive amount of data and can scales well with the increase of computational nodes.

POS-Constrained Parallel Decoding for Non-autoregressive Generation.
The multimodality problem has become a major challenge of existing non-autoregressive generation (NAG) systems. A common solution often resorts to sequence-level knowledge distillation by rebuilding the training dataset through autoregressive generation (hereinafter known as “teacher AG”). The success of such methods may largely depend on a latent assumption, i.e., the teacher AG is superior to the NAG model. However, in this work, we experimentally reveal that this assumption does not always hold for the text generation tasks like text summarization and story ending generation. To provide a feasible solution to the multimodality problem of NAG, we propose incorporating linguistic structure (Part-of-Speech sequence in particular) into NAG inference instead of relying on teacher AG. More specifically, the proposed POS-constrained Parallel Decoding (POSPD) method aims at providing a specific POS sequence to constrain the NAG model during decoding. Our experiments demonstrate that POSPD consistently improves NAG models on four text generation tasks to a greater extent compared to knowledge distillation. This observation validates the necessity of exploring the alternatives for sequence-level knowledge distillation.
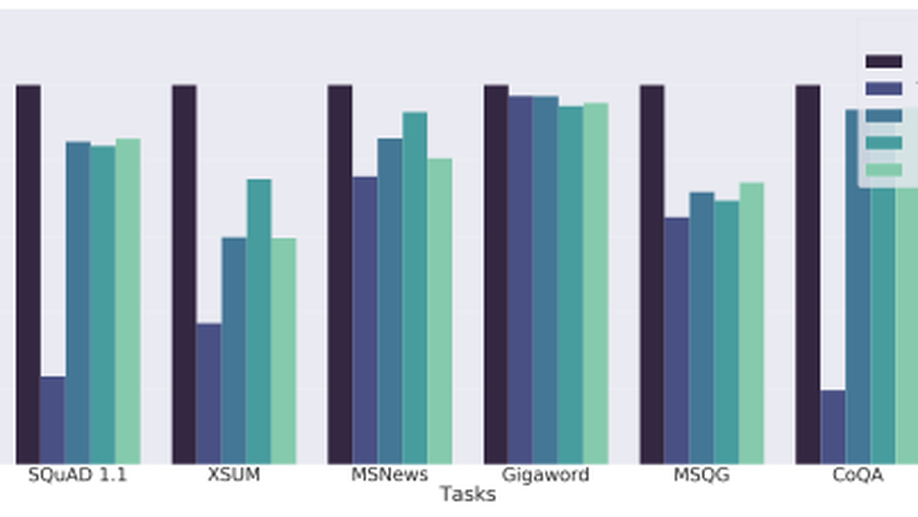
GLGE A New General Language Generation Evaluation Benchmark
Multi-task benchmarks such as GLUE and SuperGLUE have driven great progress of pretraining and transfer learning in Natural Language Processing (NLP). These benchmarks mostly focus on a range of Natural Language Understanding (NLU) tasks, without considering the Natural Language Generation (NLG) models. In this paper, we present the General Language Generation Evaluation (GLGE), a new multi-task benchmark for evaluating the generalization capabilities of NLG models across eight language generation tasks. For each task, we continue to design three subtasks in terms of task difficulty (GLGE-Easy, GLGE-Medium, and GLGE-Hard). This introduces 24 subtasks to comprehensively compare model performance. To encourage research on pretraining and transfer learning on NLG models, we make GLGE publicly available and build a leaderboard with strong baselines including MASS, BART, and ProphetNet (The source code and dataset are publicly available at this https URL).
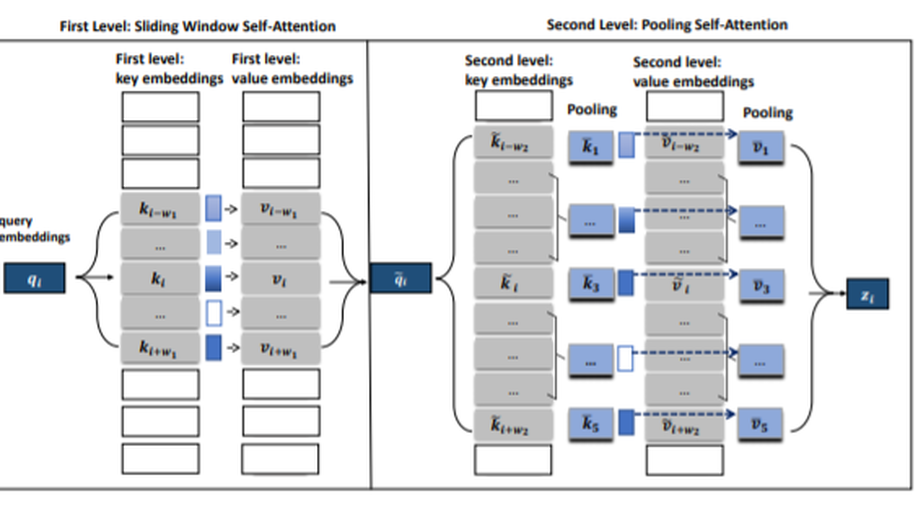
Poolingformer: Long Document Modeling with Pooling Attention.
In this paper, we introduce a two-level attention schema, Poolingformer, for long document modeling. Its first level uses a smaller sliding window pattern to aggregate information from neighbors. Its second level employs a larger window to increase receptive fields with pooling attention to reduce both computational cost and memory consumption. We first evaluate Poolingformer on two long sequence QA tasks: the monolingual NQ and the multilingual TyDi QA. Experimental results show that Poolingformer sits atop three official leaderboards measured by F1, outperforming previous state-of-the-art models by 1.9 points (79.8 vs. 77.9) on NQ long answer, 1.9 points (79.5 vs. 77.6) on TyDi QA passage answer, and 1.6 points (67.6 vs. 66.0) on TyDi QA minimal answer. We further evaluate Poolingformer on a long sequence summarization task. Experimental results on the arXiv benchmark continue to demonstrate its superior performance.
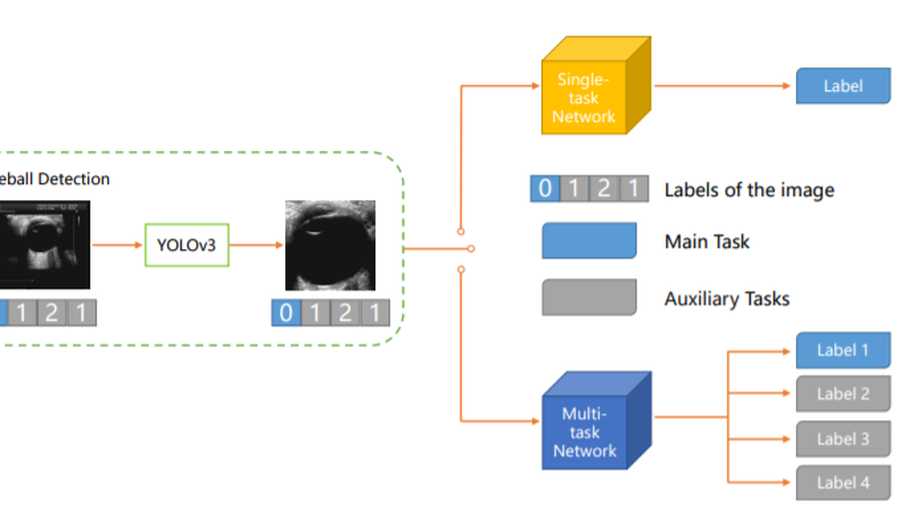
Automatic Cataract Detection with Multi-Task Learning.
Cataract is one of the most prevalent diseases among the elderly. As the population ages, the incidence of cataracts is on the rise. Early diagnosis and treatment are essential for cataracts. The routine early diagnosis relies on B-scan eye ultrasound images, developing deep learning-based automatic cataract detection makes great sense. However, ultrasound images are complex and contain irrelevant backgrounds, the lens takes up only a small part. Besides, detection networks commonly use only one label as supervision, which leads to low classification accuracy and poor generalization. This paper focuses on making the most of the information in the images, thus proposing a new paradigm for automatic cataract detection. First, an object detection network is included to locate the eyeball area and eliminate the influence of the background. Next, we construct a dataset with multiple labels for each image. We extract the text descriptions of ultrasound images into labels so that each image is tagged with multiple labels. Then we applied the multi-task learning (MTL) methods to cataract detection. The accuracy of classification is significantly improved compared to data with only one label. Last, we propose two gradient-guided auxiliary learning methods to make the auxiliary tasks improve the performance of the main task (cataract detection). The experimental results show that our proposed methods further improve the classification accuracy.
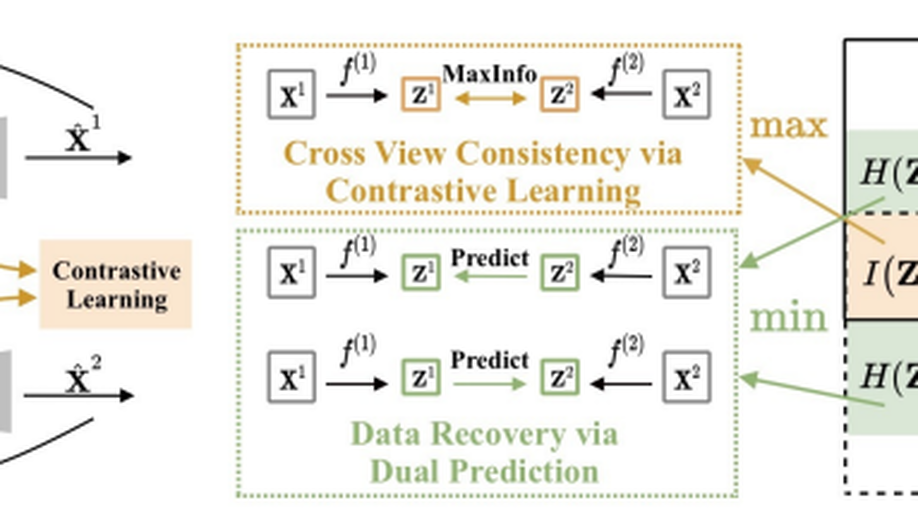
COMPLETER: Incomplete Multi-View Clustering via Contrastive Prediction.
In this paper, we study two challenging problems in incomplete multi-view clustering analysis, namely, i) how to learn an informative and consistent representation among different views without the help of labels and ii) how to recover the missing views from data. To this end, we propose a novel objective that incorporates representation learning and data recovery into a unified framework from the view of information theory. To be specific, the informative and consistent representation is learned by maximizing the mutual information across different views through contrastive learning, and the missing views are recovered by minimizing the conditional entropy of different views through dual prediction. To the best of our knowledge, this could be the first work to provide a theoretical framework that unifies the consistent representation learning and cross-view data recovery. Extensive experimental results show the proposed method remarkably outperforms 10 competitive multi-view clustering methods on four challenging datasets. The code is available at https://pengxi.me.
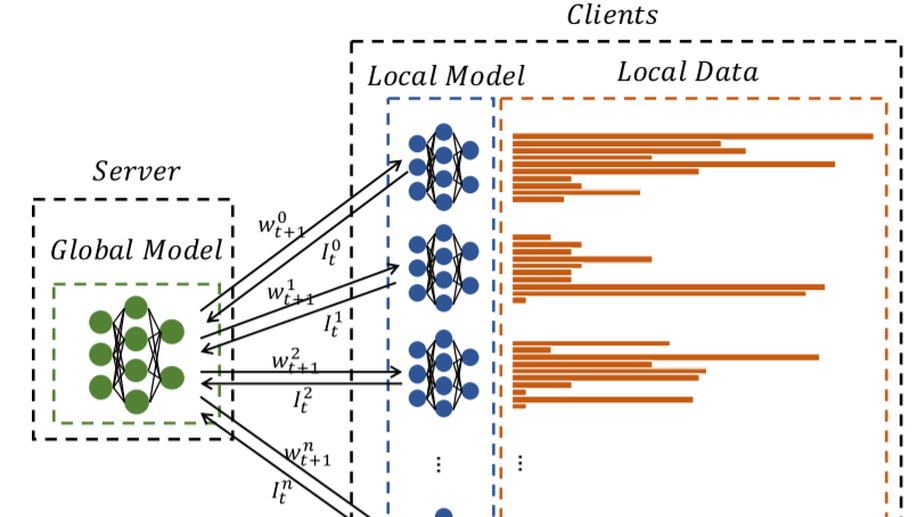
Communication-Efficient Federated Learning With Compensated Overlap-FedAvg.
While petabytes of data are generated each day by a number of independent computing devices, only a few of them can be finally collected and used for deep learning (DL) due to the apprehension of data security and privacy leakage, thus seriously retarding the extension of DL. In such a circumstance, federated learning (FL) was proposed to perform model training by multiple clients' combined data without the dataset sharing within the cluster. Nevertheless, federated learning with periodic model averaging (FedAvg) introduced massive communication overhead as the synchronized data in each iteration is about the same size as the model, and thereby leading to a low communication efficiency. Consequently, variant proposals focusing on the communication rounds reduction and data compression were proposed to decrease the communication overhead of FL. In this article, we propose Overlap-FedAvg, an innovative framework that loosed the chain-like constraint of federated learning and paralleled the model training phase with the model communication phase (i.e., uploading local models and downloading the global model), so that the latter phase could be totally covered by the former phase. Compared to vanilla FedAvg, Overlap-FedAvg was further developed with a hierarchical computing strategy, a data compensation mechanism, and a nesterov accelerated gradients (NAG) algorithm. In Particular, Overlap-FedAvg is orthogonal to many other compression methods so that they could be applied together to maximize the utilization of the cluster. Besides, the theoretical analysis is provided to prove the convergence of the proposed framework. Extensive experiments conducting on both image classification and natural language processing tasks with multiple models and datasets also demonstrate that the proposed framework substantially reduced the communication overhead and boosted the federated learning process.
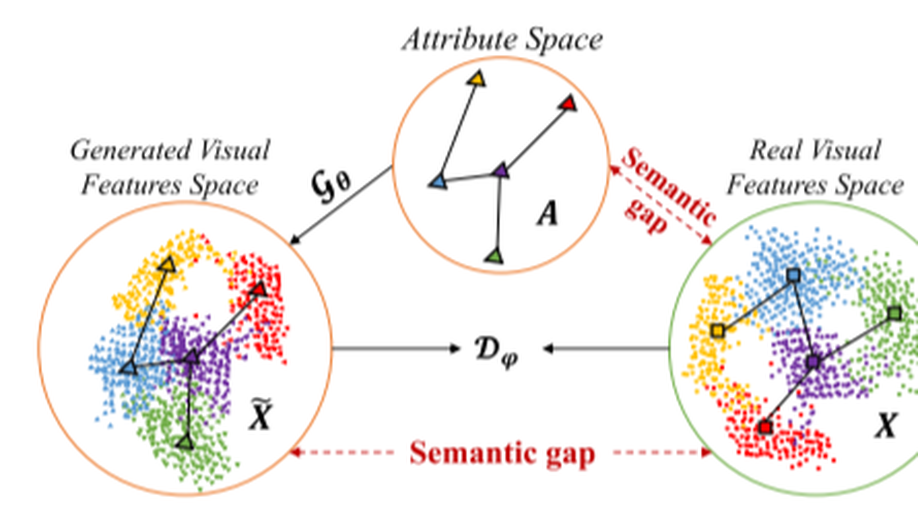
Zero-Shot Learning via Structure-Aligned Generative Adversarial Network.
In this article, we propose a structure-aligned generative adversarial network framework to improve zero-shot learning (ZSL) by mitigating the semantic gap, domain shift, and hubness problem. The proposed framework contains two parts, i.e., a generative adversarial network with a softmax classifier part, and a structure-aligned part. In the first part, the generative adversarial network aims at generating pseudovisual features through the guiding generator and discriminator play the minimax two-player game together. At the same time, the softmax classifier is committed to increasing the interclass distance and reducing intraclass distance. Then, the harmful effect of domain shift and hubness problems can be mitigated. In another part, we introduce a structure-aligned module where the structural consistency between visual space and semantic space is learned. By aligning the structure between visual space and semantic space, the semantic gap between them can be bridged. The performance of classification is improved when the structure-aligned visual-semantic embedding space is transferred to the unseen classes. Our framework reformulates the ZSL as a standard fully supervised classification task using the pseudovisual features of unseen classes. Extensive experiments conducted on five benchmark data sets demonstrate that the proposed framework significantly outperforms state-of-the-art methods in both conventional and generalized settings.
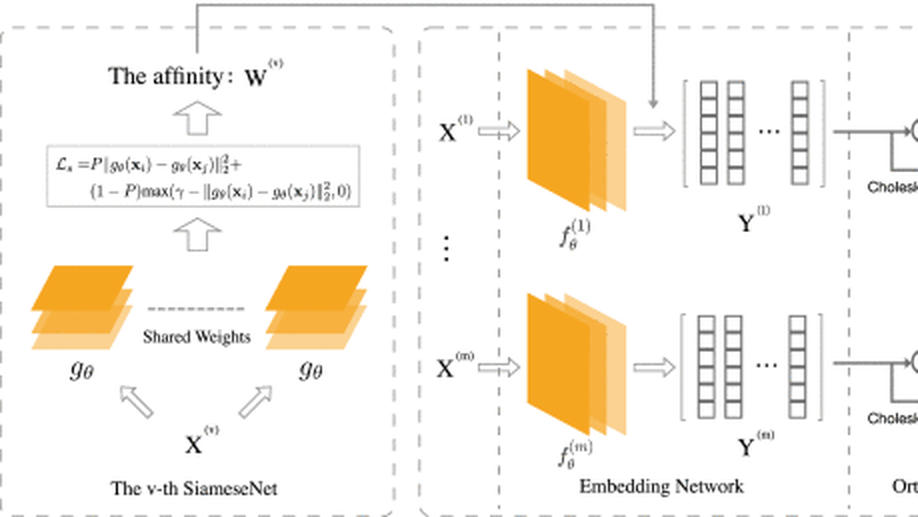
Deep Spectral Representation Learning From Multi-View Data.
Multi-view representation learning (MvRL) aims to learn a consensus representation from diverse sources or domains to facilitate downstream tasks such as clustering, retrieval, and classification. Due to the limited representative capacity of the adopted shallow models, most existing MvRL methods may yield unsatisfactory results, especially when the labels of data are unavailable. To enjoy the representative capacity of deep learning, this paper proposes a novel multi-view unsupervised representation learning method, termed as Multi-view Laplacian Network (MvLNet), which could be the first deep version of the multi-view spectral representation learning method. Note that, such an attempt is nontrivial because simply combining Laplacian embedding (i.e., spectral representation) with neural networks will lead to trivial solutions. To solve this problem, MvLNet enforces an orthogonal constraint and reformulates it as a layer with the help of Cholesky decomposition. The orthogonal layer is stacked on the embedding network so that a common space could be learned for consensus representation. Compared with numerous recent-proposed approaches, extensive experiments on seven challenging datasets demonstrate the effectiveness of our method in three multi-view tasks including clustering, recognition, and retrieval. The source code could be found at www.pengxi.me.
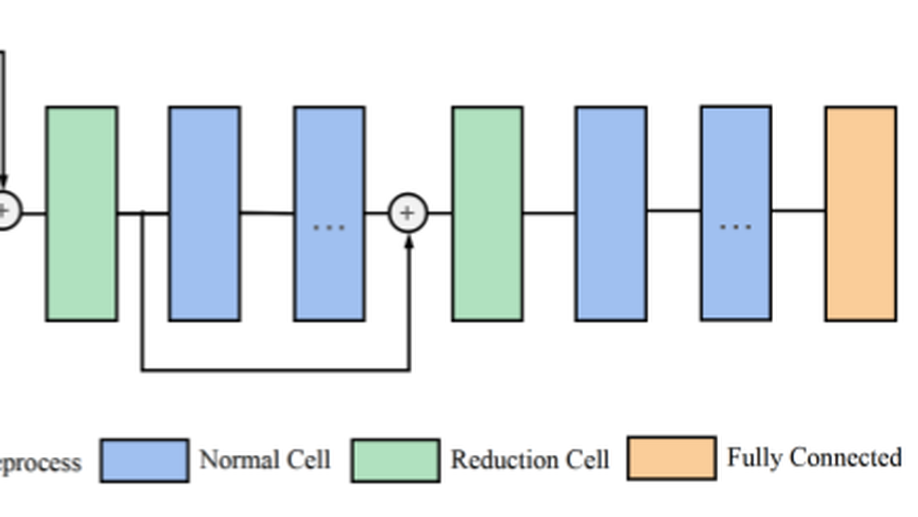
Heart-Darts: Classification of Heartbeats Using Differentiable Architecture Search.
Arrhythmia is a cardiovascular disease that manifests irregular heartbeats. In arrhythmia detection, the electrocardiogram (ECG) signal is an important diagnostic technique. However, manually evaluating ECG signals is a complicated and time-consuming task. With the application of convolutional neural networks (CNNs), the evaluation process has been accelerated and the performance is improved. It is noteworthy that the performance of CNNs heavily depends on their architecture design, which is a complex process grounded on expert experience and trial-and-error. In this paper, we propose a novel approach, Heart-Darts, to efficiently classify the ECG signals by automatically designing the CNN model with the differentiable architecture search (i.e., Darts, a cell-based neural architecture search method). Specifically, we initially search a cell architecture by Darts and then customize a novel CNN model for ECG classification based on the obtained cells. To investigate the efficiency of the proposed method, we evaluate the constructed model on the MIT-BIH arrhythmia database. Additionally, the extensibility of the proposed CNN model is validated on two other new databases. Extensive experimental results demonstrate that the proposed method outperforms several state-of-the-art CNN models in ECG classification in terms of both performance and generalization capability.

LANA: Towards Personalized Deep Knowledge Tracing Through Distinguishable Interactive Sequences.
In educational applications, Knowledge Tracing (KT), the problem of accurately predicting students' responses to future questions by summarizing their knowledge states, has been widely studied for decades as it is considered a fundamental task towards adaptive online learning. Among all the proposed KT methods, Deep Knowledge Tracing (DKT) and its variants are by far the most effective ones due to the high flexibility of the neural network. However, DKT often ignores the inherent differences between students (e.g. memory skills, reasoning skills, …), averaging the performances of all students, leading to the lack of personalization, and therefore was considered insufficient for adaptive learning. To alleviate this problem, in this paper, we proposed Leveled Attentive KNowledge TrAcing (LANA), which firstly uses a novel student-related features extractor (SRFE) to distill students' unique inherent properties from their respective interactive sequences. Secondly, the pivot module was utilized to dynamically reconstruct the decoder of the neural network on attention of the extracted features, successfully distinguishing the performance between students over time. Moreover, inspired by Item Response Theory (IRT), the interpretable Rasch model was used to cluster students by their ability levels, and thereby utilizing leveled learning to assign different encoders to different groups of students. With pivot module reconstructed the decoder for individual students and leveled learning specialized encoders for groups, personalized DKT was achieved. Extensive experiments conducted on two real-world large-scale datasets demonstrated that our proposed LANA improves the AUC score by at least 1.00% (i.e. EdNet 1.46% and RAIEd2020 1.00%), substantially surpassing the other State-Of-The-Art KT methods.
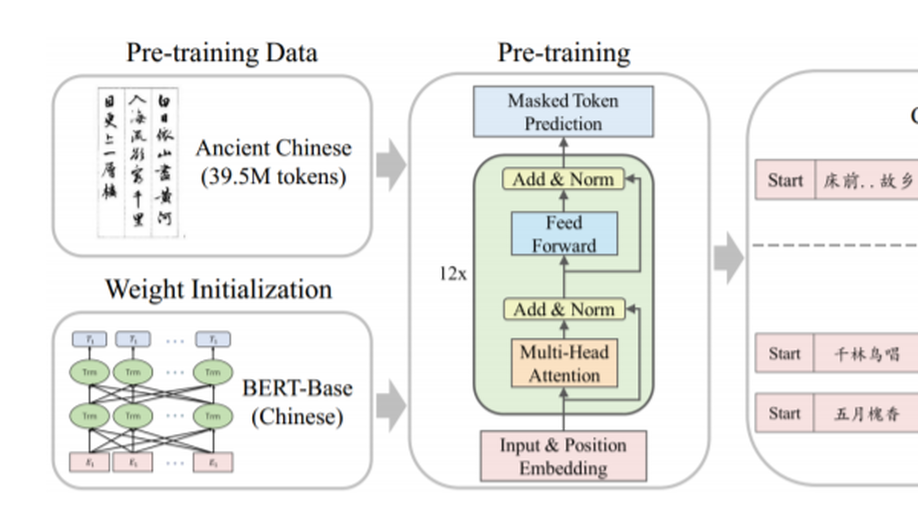
AnchiBERT: A Pre-Trained Model for Ancient Chinese Language Understanding and Generation.
Ancient Chinese is the essence of Chinese culture. There are several natural language processing tasks of ancient Chinese domain, such as ancient-modern Chinese translation, poem generation, and couplet generation. Previous studies usually use the supervised models which deeply rely on parallel data. However, it is difficult to obtain large-scale parallel data of ancient Chinese. In order to make full use of the more easily available monolingual ancient Chinese corpora, we release An-chiBERT, a pre-trained language model based on the architecture of BERT, which is trained on large-scale ancient Chinese corpora. We evaluate AnchiBERT on both language understanding and generation tasks, including poem classification, ancient-modern Chinese translation, poem generation, and couplet generation. The experimental results show that AnchiBERT outperforms BERT as well as the non-pretrained models and achieves state-of - the-art results in all cases.
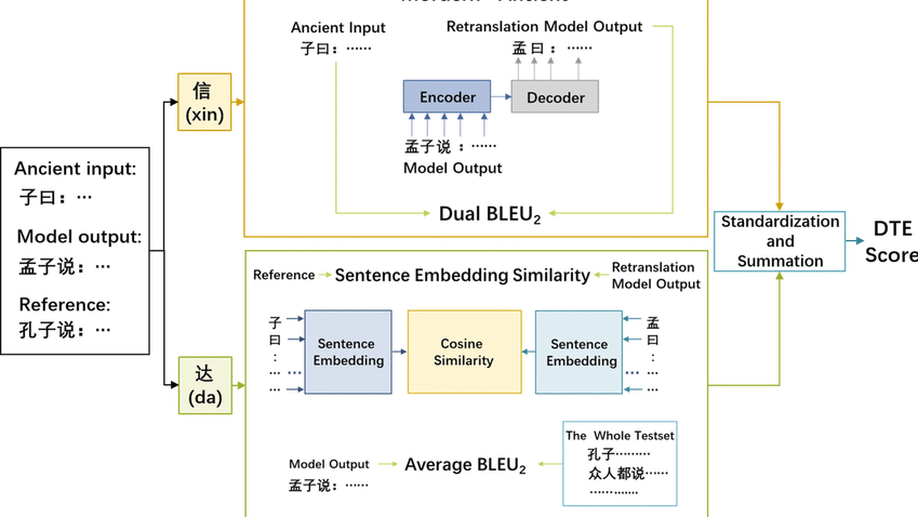
An automatic evaluation metric for Ancient-Modern Chinese translation.
As a written language used for thousands of years, Ancient Chinese has some special characteristics like complex semantics as polysemy and the one-to-many alignment with Modern Chinese. Thus it may be translated in a large number of fully different but equally correct ways. In the absence of multiple references, reference-dependent evaluations like Bilingual Evaluation Understudy (BLEU) cannot identify potentially correct translation results. The explore on automatic evaluation of Ancient-Modern Chinese Translation is completely lacking. In this paper, we proposed an automatic evaluation metric for Ancient-Modern Chinese Translation called DTE (Dual-based Translation Evaluation), which can be used to evaluate one-to-many alignment in the absence of multiple references. When using DTE to evaluate, we found that the proper nouns often could not be correctly translated. Hence, we designed a new word segmentation method to improve the translation of proper nouns without increasing the size of the model vocabulary. Experiments show that DTE outperforms several general evaluations in terms of similarity to the evaluation of human experts. Meanwhile, the new word segmentation method promotes the Ancient-Modern Chinese translation models perform better on proper nouns’ translation, and get higher scores on both BLEU and DTE.
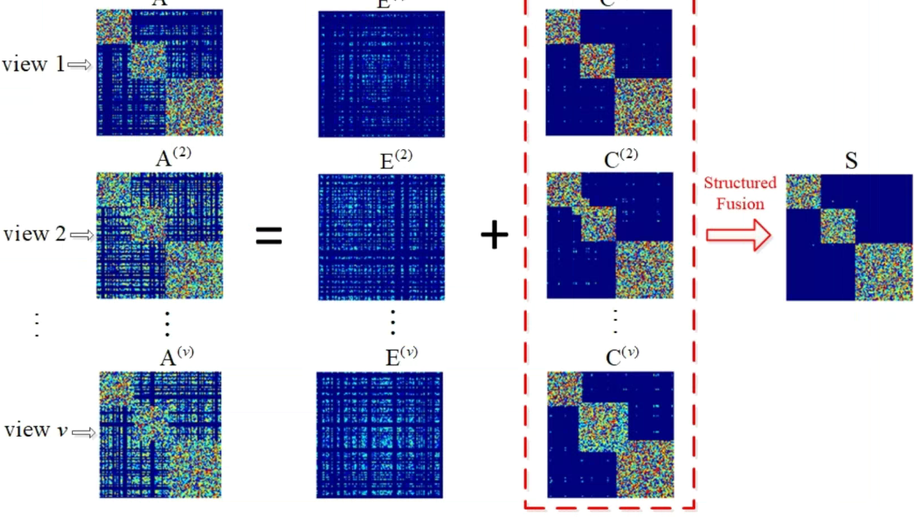
Measuring Diversity in Graph Learning: A Unified Framework for Structured Multi-view Clustering.
Graph Learning has emerged as a promising technique for multi-view clustering due to its efficiency of learning a unified graph from multiple views. Previous multi-view graph learning methods mainly try to exploit the multi-view consistency to boost learning performance. However, these methods ignore the prevalent multi-view diversity which may be induced by noise, corruptions, or even view-specific attributes. In this paper, we propose to simultaneously and explicitly leverage the multi-view consistency and the multi-view diversity in a unified framework. The consistent parts are further fused to our target graph with a clear clustering structure, on which the cluster label to each instance can be directly allocated without any postprocessing such as k-means in classical spectral clustering. In addition, our model can automatically assign suitable weight for each view based on its clustering capacity. By leveraging the subtasks of measuring the diversity of graphs, integrating the consistent parts with automatically learned weights, allocating cluster label to each instance in a joint framework, each subtask can be alternately boosted by utilizing the results of the others towards an overall optimal solution. Extensive experimental results on several benchmark multi-view datasets demonstrate the effectiveness of our model in comparison to several state-of-the-art algorithms.
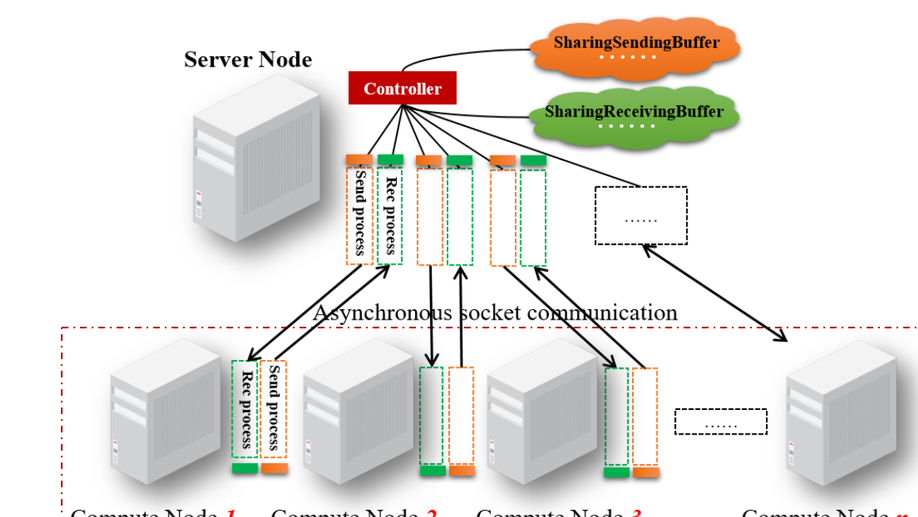
A distributed framework for EA-based NAS.
Evolutionary Algorithms(EA) are widely applied in Neural Architecture Search(NAS) and have achieved appealing results. Different EA-based NAS algorithms may utilize different encoding schemes for network representation, while they have the same workflow (i.e., the initialization of the population, individual evaluation, and evolution). Because each individual needs complete training and validation on the target dataset, the EA-based NAS always consumes significant computation and time inevitably, which results in the bottleneck of this approach. To ameliorate this issue, this paper proposes a distributed framework to boost the computing of the EA-based NAS. This framework is a server/worker model where the server distributes individuals, collects the validated individuals and hosts the evolution operations. Meanwhile, the most time-consuming phase (i.e., individual evaluation) is allocated to the computational workers. Additionally, a new packet structure of the message delivered in the cluster is designed to encapsulate various network representation of different EA-based NAS algorithms. We design an EA-based NAS algorithm as a sample to investigate the effectiveness of the proposed framework. Extensive experiments are performed on an illustrative cluster with different scales, and the results reveal that the framework can achieve a nearly linear reduction of the training time with the increase of the computational workers.
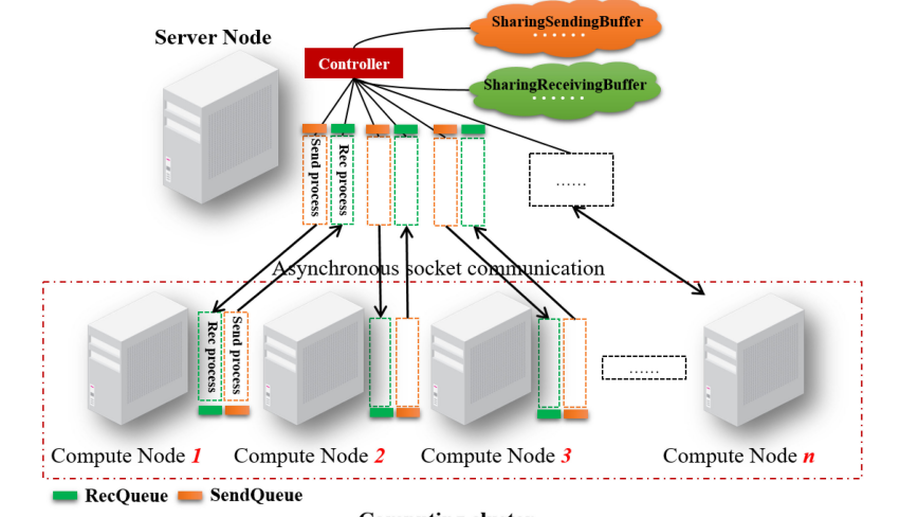
A Distributed Framework for EA-Based NAS.
Evolutionary Algorithms (EA) are widely applied in Neural Architecture Search (NAS) and have achieved appealing results. Different EA-based NAS algorithms may utilize different encoding schemes for network representation, while they have the same workflow. Specifically, the first step is the initialization of the population with different encoding schemes, and the second step is the evaluation of the individuals by the fitness function. Then, the EA-based NAS algorithm executes evolution operations, e.g., selection, mutation, and crossover, to eliminate weak individuals and generate more competitive ones. Lastly, evolution continues until the max generation and the best neural architectures will be chosen. Because each individual needs complete training and validation on the target dataset, the EA-based NAS always consumes significant computation and time inevitably, which results in the bottleneck of this approach. To ameliorate this issue, this article proposes a distributed framework to boost the computation of the EA-based NAS algorithm. This framework is a server/worker model where the server distributes individuals requested by the computing nodes and collects the validated individuals and hosts the evolution operations. Meanwhile, the most time-consuming phase (i.e., individual evaluation) of the EA-based NAS is allocated to the computing nodes, which send requests asynchronously to the server and evaluate the fitness values of the individuals. Additionally, a new packet structure of the message delivered in the cluster is designed to encapsulate various network representations and support different EA-based NAS algorithms. We design an EA-based NAS algorithm as a case to investigate the efficiency of the proposed framework. Extensive experiments are performed on an illustrative cluster with different scales, and the results reveal that the framework can achieve a nearly linear reduction of the search time with the increase of the computational nodes.Furthermore, the length of the exchanged messages among the cluster is tiny, which benefits the framework expansion.
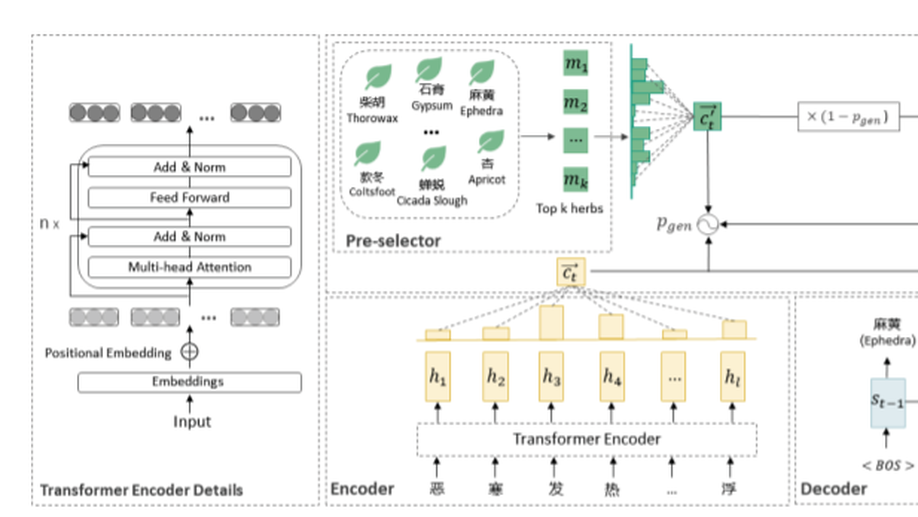
Herb-Know: Knowledge Enhanced Prescription Generation for Traditional Chinese Medicine.
Prescription generation of traditional Chinese medicine (TCM) is a meaningful and challenging problem. Previous researches mainly model the relationship between symptoms and herbal prescription directly. However, TCM practitioners often take herb effects into consideration when prescribing. Few works focus on fusing the external knowledge of herbs. In this paper, we explore how to generate a prescription with the knowledge of herb effects under the given symptoms. We propose Herb-Know, a sequence to sequence (seq2seq) model with pointer network, where the prescription is conditioned over two inputs (symptoms and pre-selected herb candidates). To the best of our knowledge, this is the first attempt to generate a prescription with a knowledge enhanced seq2seq model. The experimental results demonstrate that our method can make use of knowledge to generate informative and reasonable herbs, which outperforms other baseline models.

Multi‐style Chinese art painting generation of flowers.
With the proposal and development of Generative Adversarial Networks, the great achievements in the field of image generation are made. Meanwhile, many works related to the generation of painting art have also been derived. However, due to the difficulty of data collection and the fundamental challenge from freehand expressions, the generation of traditional Chinese painting is still far from being perfect. This paper specialises in Chinese art painting generation of flowers, which is important and classic, by deep learning method. First, an unpaired flowers paintings data set containing three classic Chinese painting style: line drawing, meticulous, and ink is constructed. Then, based on the collected dataset, a Flower-Generative Adversarial Network framework to generate multi-style Chinese art painting of flowers is proposed. The Flower-Generative Adversarial Network, consisting of attention-guided generators and discriminators, transfers the style among line drawing, meticulous, and ink by an adversarial training way. Moreover, in order to solve the problem of artefact and blur in image generation by existing methods, a new loss function called Multi-Scale Structural Similarity to force the structure preservation is introduced. Extensive experiments show that the proposed Flower-Generative Adversarial Network framework can produce better and multi-style Chinese art painting of flowers than existing methods.
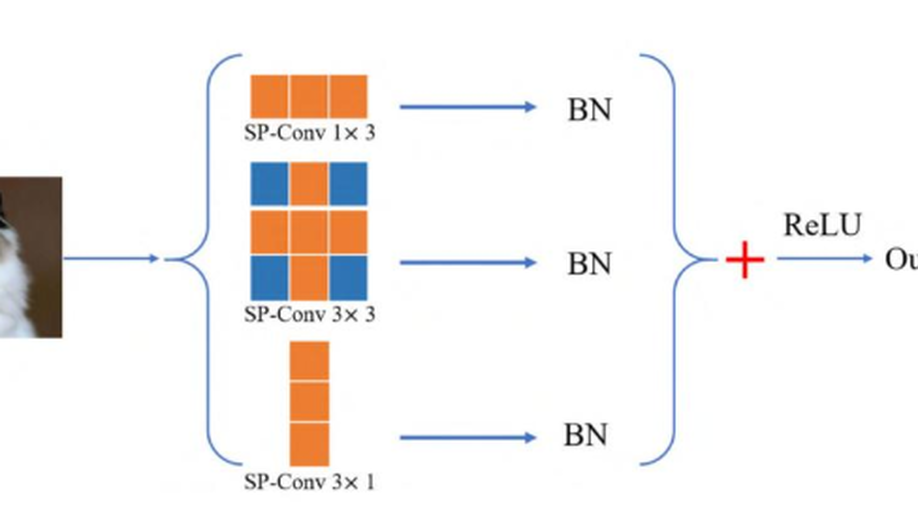
SuperConv Strengthening the Convolution Kernel via Weight Sharing.
For the current neural network models, in order to improve the accuracy of the models, we need efficient plug-and-play modules. Therefore, many efficient plug-and-play operations are proposed, such as Asymmetric Convolution Block (ACB). However, the introduction of multi-branch convolution kernels in ACB increases the trainable parameters, which is an extra burden to the training of large models. In this work, SuperConv is proposed to reduce the trainable parameters while maintaining the advantages of ACB. SuperConv utilizes the method in single-path NAS to encode the convolution kernels of different sizes in multiple branches into a super-kernel, so that the convolution kernels can share some weights with each other. In addition, we introduce SuperConv into MixConv and propose SuperMixConv (SP-MixConv). To verify the effectiveness of SP-MixConv, ACB, MixConv and SP-MixConv are inserted into the Cifar-quick model and the model with SP-MixConv gets the best accuracy on CIFAR-10 and CIFAR-100. And SuperConv and SP-MixConv will not add extra burden in inference. Simultaneously, SuperConv is very easy to implement, using existing tools such as Pytorch, and is also an interesting attempt for the design of efficient plug-and-play convolution block.
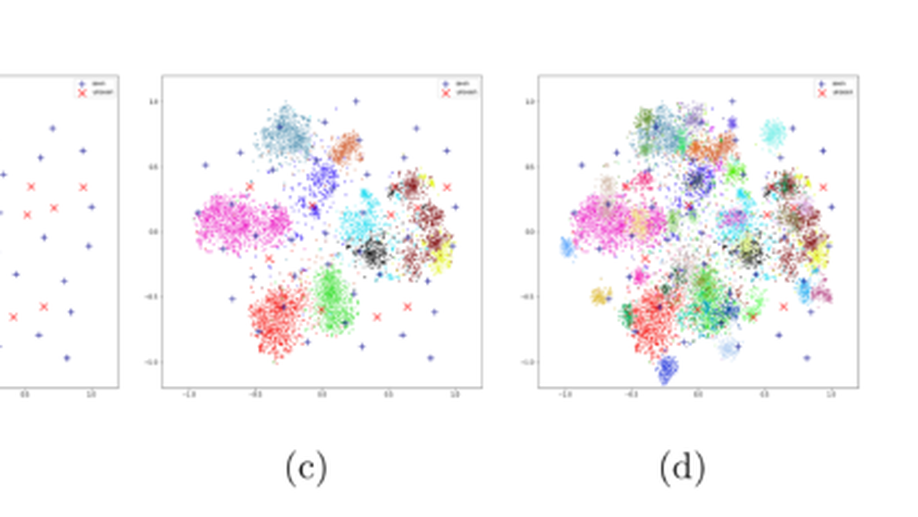
SAN Sampling Adversarial Networks for Zero-Shot Learning.
In this paper, we propose a Sampling Adversarial Networks (SAN) framework to improve Zero-Shot Learning (ZSL) by mitigating the hubness and semantic gap problem. The SAN framework incorporates a sampling model and a discriminating model, and corresponds them to the minimax two-player game. Specifically, given the semantic embedding, the sampling model samples the visual features from the training set to approach the discriminator’s decision boundary. Then, the discriminator distinguishes the matching visual-semantic pairs from the sampled data. On the one hand, by the measurement of the matching degree of visual-semantic pairs and the adversarial training way, the visual-semantic embedding built by the proposed SAN decreases the intra-class distance and increases the inter-class separation. Then, the reduction of universal neighbours in the visual-semantic embedding subspace alleviates the hubness problem. On the other, the sampled rather than directly generated visual features maintain the same manifold as the real data, mitigating the semantic gap problem. Experiments show that the sampler and discriminator of the SAN framework outperform state-of-the-art methods both in conventional and generalized ZSL settings.
Key Factors of Email Subject Generation.
Automatic email subject generation is of great significance to both the recipient and the email system. The method of using deep neural network to solve the automatically generated task of email subject line has been proposed recently. We experimentally explored the performance impact of multiple elements in this task. These experimental results will provide some guiding significance for the future research of this task. As far as we know, this is the first work to study and analyze the effects of related elements.
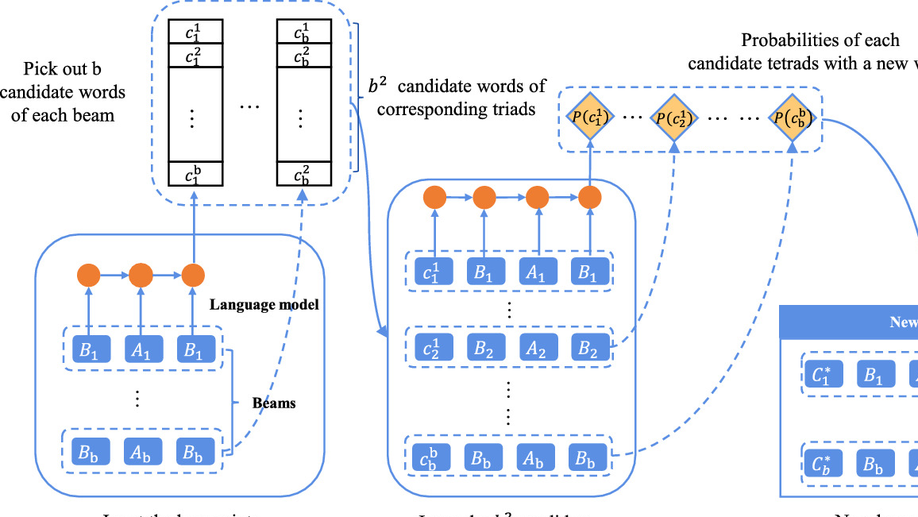
Exploration on the Generation of Chinese Palindrome Poetry.
Recently, Chinese poetry generation gains many significant achievement with the development of deep learning. However, existing methods can not generate Chinese palindrome poetry. Besides, there is no public dataset of Chinese palindrome poetry. In this paper, we propose a novel Chinese palindrome poetry generation model, named Chinese Palindrome Poetry Generation Model (CPPGM), based on the universal seq2seq model and language model with specific beam search algorithms. In addition, the proposed model is the first to generate Chinese palindrome poetry automatically, and is applicable to other palindromes, such as palindrome couplets. Compared with several methods we propose, the experimental results demonstrate the superiority of CPPGM with machine evaluation as well as human judgment.
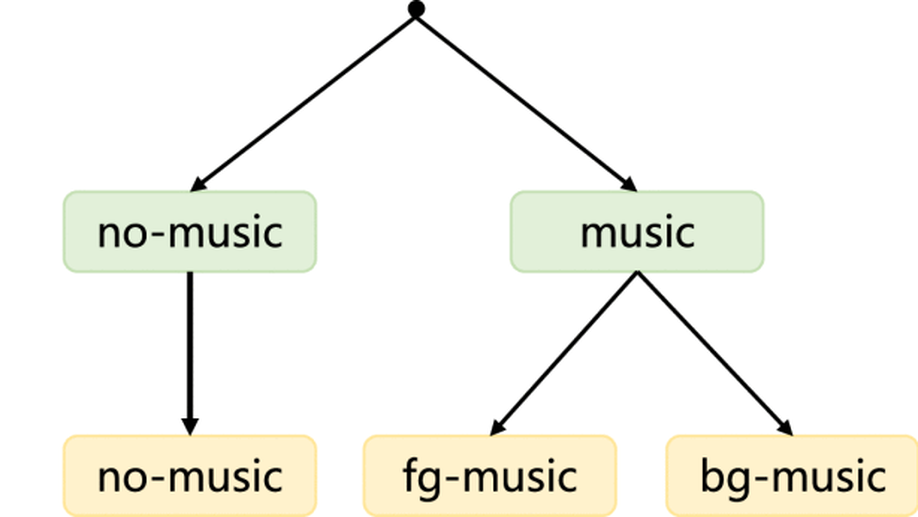
Hierarchical Regulated Iterative Network for Joint Task of Music Detection and Music Relative Loudness Estimation.
One practical requirement of the music copyright management is the estimation of music relative loudness, which is mostly ignored in existing music detection works. To solve this problem, we study the joint task of music detection and music relative loudness estimation. To be specific, we observe that the joint task has two characteristics, i.e., temporality and hierarchy, which could facilitate to obtain the solution. For example, a tiny fragment of audio is temporally related to its neighbor fragments because they may all belong to the same event, and the event classes of the fragment in the two tasks have a hierarchical relationship. Based on the above observation, we reformulate the joint task as hierarchical event detection and localization problem. To solve this problem, we further propose Hierarchical Regulated Iterative Networks (HRIN), which includes two variants, termed as HRIN-r and HRIN-cr, which are based on recurrent and convolutional recurrent modules. To enjoy the joint task’s characteristics, our models employ an iterative framework to achieve encouraging capability in temporal modeling while designing three hierarchical violation penalties to regulate hierarchy. Extensive experiments on the currently largest dataset (i.e., OpenBMAT) show that the promising performance of our HRIN in the segment-level and event-level evaluations.
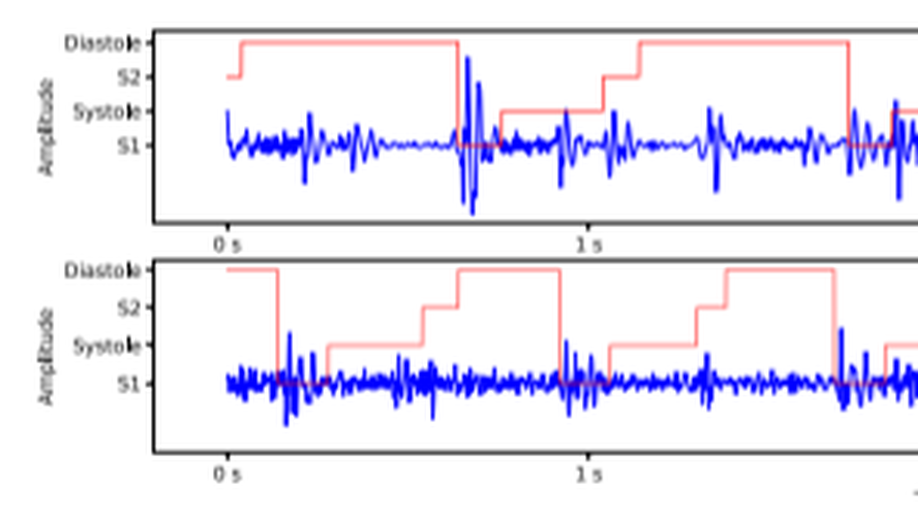
Heart sound segmentation via Duration Long–Short Term Memory neural network.
Heart sound segmentation, which aims at detecting the first and second heart sound in phonocardiogram, is an essential step to automatically analyze heart valve diseases. Recently, the neural network-based methods have demonstrated their promising performance in segmenting the heart sound data. However, the methods also suffer from serious limitations due to the used envelope features. The reason is largely due to that the envelope features cannot effectively model the intrinsic sequential characteristic, resulting in the poor utilization of the duration information of heart cycles. In this paper, we propose a Duration Long–Short Term Memory network (Duration LSTM) to effectively address this problem by incorporating the duration features. The proposed method is investigated in the real-world phonocardiogram dataset (Massachusetts Institute of Technology heart sounds database) and compared with the two representatives of the existing state-of-the-art methods, the experimental results demonstrate that the proposed method has the promising performance on different tolerance windows. In addition, the proposed model also has some advantages in the impact of recording length and the phenomenon of the end effect.
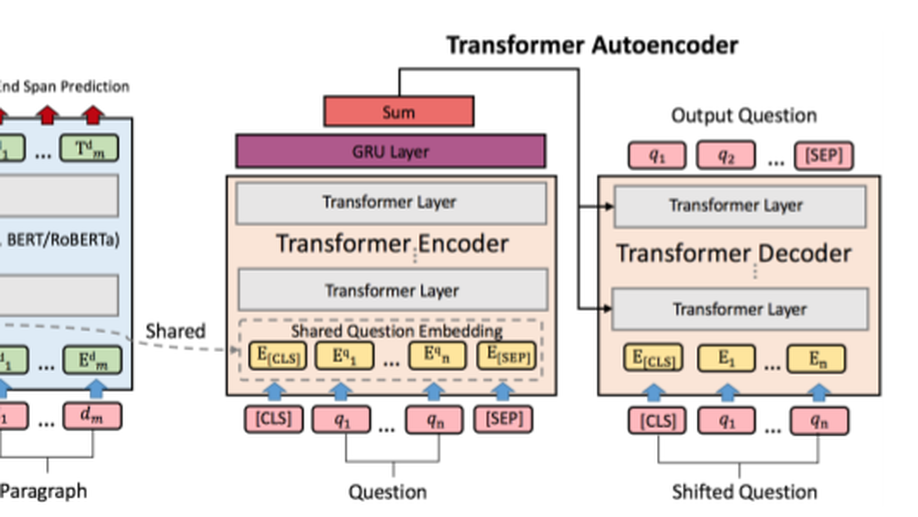
Tell Me How to Ask Again: Question Data Augmentation with Controllable Rewriting in Continuous Space.
In this paper, we propose a novel data augmentation method, referred to as Controllable Rewriting based Question Data Augmentation (CRQDA), for machine reading comprehension (MRC), question generation, and question-answering natural language inference tasks. We treat the question data augmentation task as a constrained question rewriting problem to generate context-relevant, high-quality, and diverse question data samples. CRQDA utilizes a Transformer Autoencoder to map the original discrete question into a continuous embedding space. It then uses a pre-trained MRC model to revise the question representation iteratively with gradient-based optimization. Finally, the revised question representations are mapped back into the discrete space, which serve as additional question data. Comprehensive experiments on SQuAD 2.0, SQuAD 1.1 question generation, and QNLI tasks demonstrate the effectiveness of CRQDA.
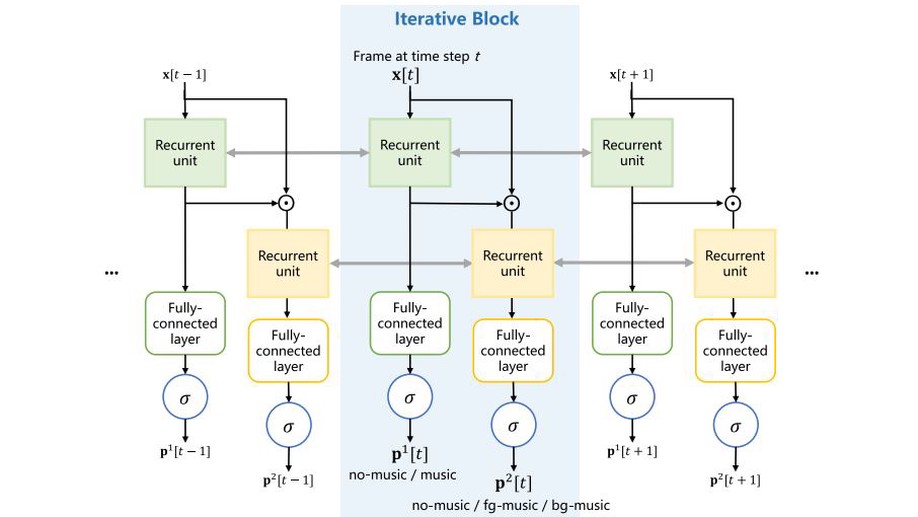
Hierarchical Regulated Iterative Network for Joint Task of Music Detection and Music Relative Loudness Estimation.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum. Sed ac faucibus dolor, scelerisque sollicitudin nisi. Cras purus urna, suscipit quis sapien eu, pulvinar tempor diam. Quisque risus orci, mollis id ante sit amet, gravida egestas nisl. Sed ac tempus magna. Proin in dui enim. Donec condimentum, sem id dapibus fringilla, tellus enim condimentum arcu, nec volutpat est felis vel metus. Vestibulum sit amet erat at nulla eleifend gravida.
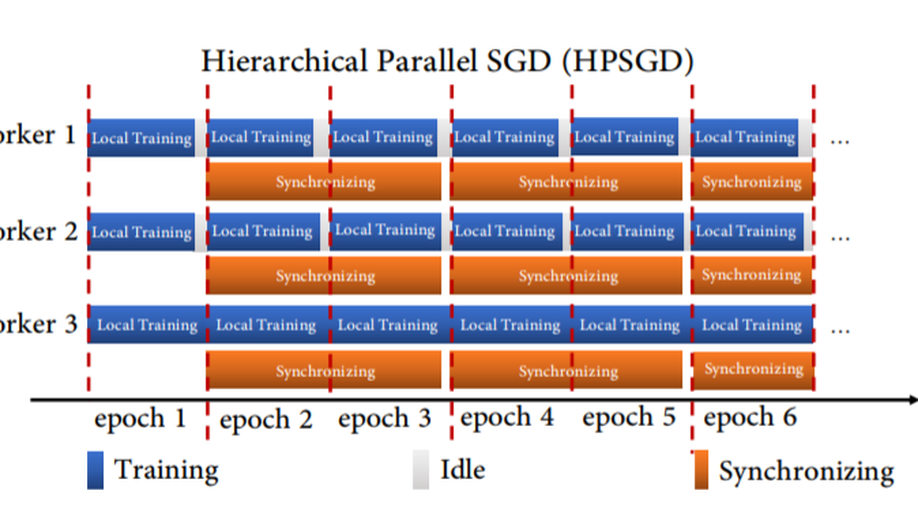
Hierarchical Parallel SGD with Stale Gradients Featuring.
While distributed training significantly speeds up the training process of the deep neural network (DNN), the utilization of the cluster is relatively low due to the time-consuming data synchronizing between workers. To alleviate this problem, a novel Hierarchical Parallel SGD (HPSGD) strategy is proposed based on the observation that the data synchronization phase can be paralleled with the local training phase (i.e., Feed-forward and back-propagation). Furthermore, an improved model updating method is unitized to remedy the introduced stale gradients problem, which commits updates to the replica (i.e., a temporary model that has the same parameters as the global model) and then merges the average changes to the global model. Extensive experiments are conducted to demonstrate that the proposed HPSGD approach substantially boosts the distributed DNN training, reduces the disturbance of the stale gradients and achieves better accuracy in given fixed wall-time.
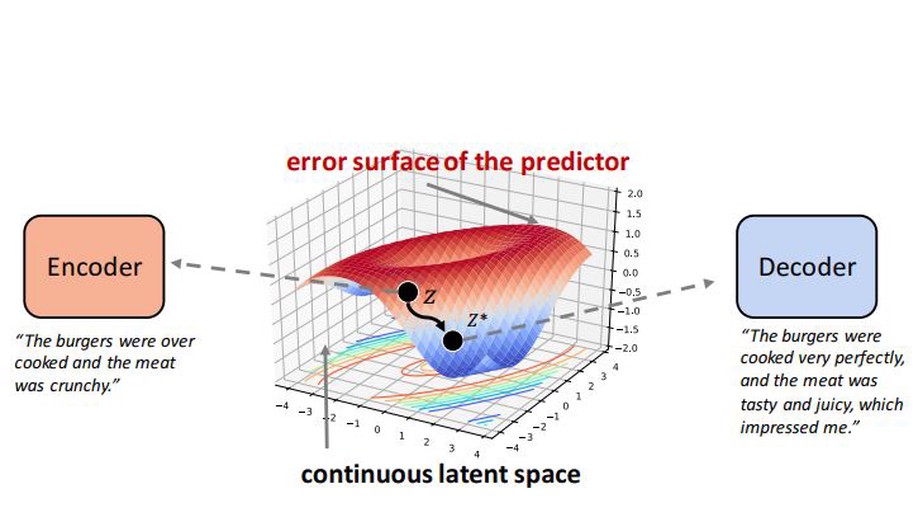
Revision in Continuous Space: Unsupervised Text Style Transfer without Adversarial Learning
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum. Sed ac faucibus dolor, scelerisque sollicitudin nisi. Cras purus urna, suscipit quis sapien eu, pulvinar tempor diam. Quisque risus orci, mollis id ante sit amet, gravida egestas nisl. Sed ac tempus magna. Proin in dui enim. Donec condimentum, sem id dapibus fringilla, tellus enim condimentum arcu, nec volutpat est felis vel metus. Vestibulum sit amet erat at nulla eleifend gravida.
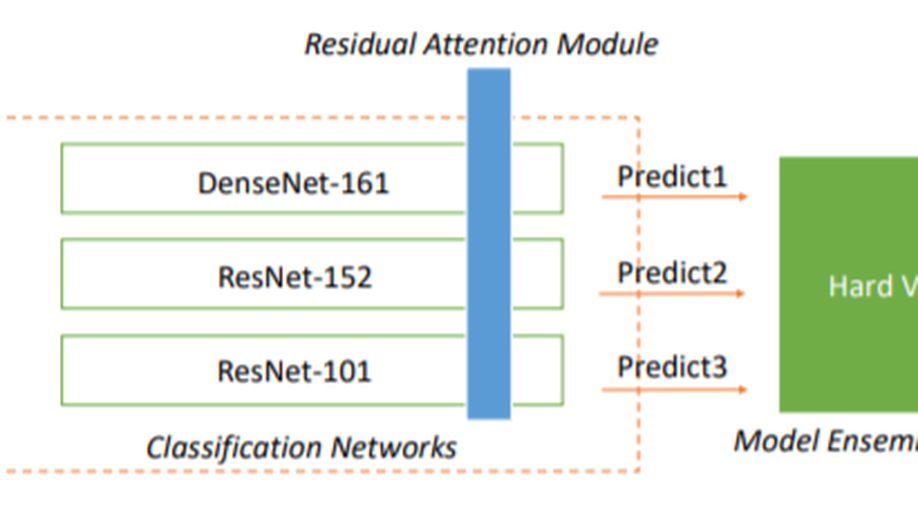
Attention-Based Multi-Model Ensemble for Automatic Cataract Detection in B-Scan Eye Ultrasound Images.
Accurate detection of early-stage cataract is essential for preventing blindness, but clinical cataract diagnosis requires the professional knowledge of experienced ophthalmologists, which may present difficulties for cataract patients in poverty-stricken areas. Deep learning method has been successful in many image classification tasks, but there are still huge challenges in the field of automatic cataract detection due to two characteristics of cataract and its B-scan eye ultrasound images. First, cataract is a disease that occurs in the lens of the eyeball, but the eyeball occupies only a small part of the eye B-ultrasound image. Second, lens lesions in eye B-ultrasound images are diverse, resulting in small difference and high similarity between positive and negative samples. In this paper, we propose a multi-model ensemble method based on residual attention for cataract classification. The proposed model consists of an object detection network, three pre-trained classification networks: DenseNet-161, ResNet-152 and ResNet-101, and a model ensemble module. Each classification network incorporates a residual attention module. Experimental results on the benchmark B-scan eye ultrasound dataset show that our method can adaptively focus on the discriminative areas of cataract in the eyeball and achieves an accuracy of 97.5%, which is markedly superior to the five baseline methods.
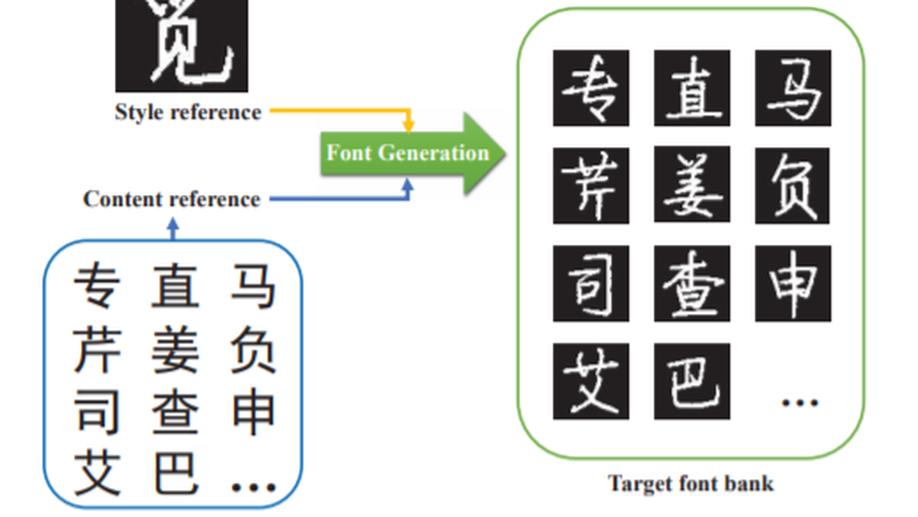
Arbitrary Chinese Font Generation from a Single Reference.
Generating a new Chinese font from a multitude of references is an easy task, while it is quite difficult to generate it from a few references. In this paper, we investigate the problem of arbitrary Chinese font generation from a single reference and propose a deep learning based model, named One-reference Chinese Font Generation Network (OCFGNet), to automatically generate any arbitrary Chinese font from a single reference. Based on the disentangled representation learning, we separate the representations of stylized Chinese characters into style and content representations. Then we design a neural network consisting of the style encoder, the content encoder and the joint decoder for the proposed model. The style encoder extracts the style features of style references and maps them onto a continuous Variational Auto-Encoder (VAE) latent variable space while the content encoder extracts the content features of content references and maps them to the content representations. Finally, the joint decoder concatenates both representations in layer-wise to generate the character which has the style of style reference and the content of content reference. In addition, based on Generative Adversarial Network (GAN) structure, we adopt a patch-level discriminator to distinguish whether the received character is real or fake. Besides the adversarial loss, we not only adopt L1-regularized per-pix loss, but also combine a novel loss term Structural SIMilarity (SSIM) together to further drive our model to generate clear and satisfactory results. The experimental results demonstrate that the proposed model can not only extract style and content features well, but also have good performance in the generation of Chinese fonts from a single reference.
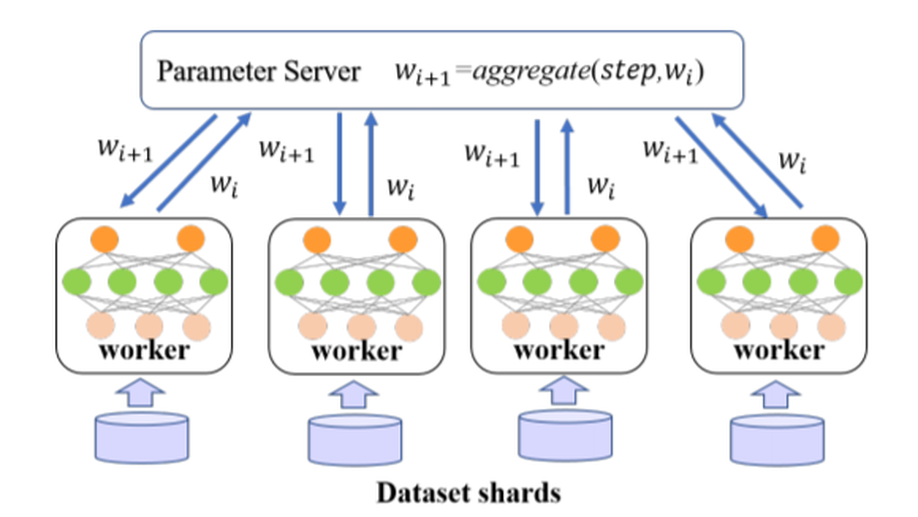
PSO-PSParameter Synchronization with Particle Swarm Optimization for Distributed Training of Deep Neural Networks.
Parameter updating is an important stage in parallelism-based distributed deep learning. Synchronous methods are widely used in distributed training the Deep Neural Networks (DNNs). To reduce the communication and synchronization overhead of synchronous methods, decreasing the synchronization frequency (e.g., every n mini-batches) is a straightforward approach. However, it often suffers from poor convergence. In this paper, we propose a new algorithm of integrating Particle Swarm Optimization (PSO) into the distributed training process of DNNs to automatically compute new parameters. In the proposed algorithm, a computing work is encoded by a particle, the weights of DNNs and the training loss are modeled by the particle attributes. At each synchronization stage, the weights are updated by PSO from the sub weights gathered from all workers, instead of averaging the weights or the gradients. To verify the performance of the proposed algorithm, the experiments are performed on two commonly used image classification benchmarks: MNIST and CIFAR10, and compared with the peer competitors at multiple different synchronization configurations. The experimental results demonstrate the competitiveness of the proposed algorithm.
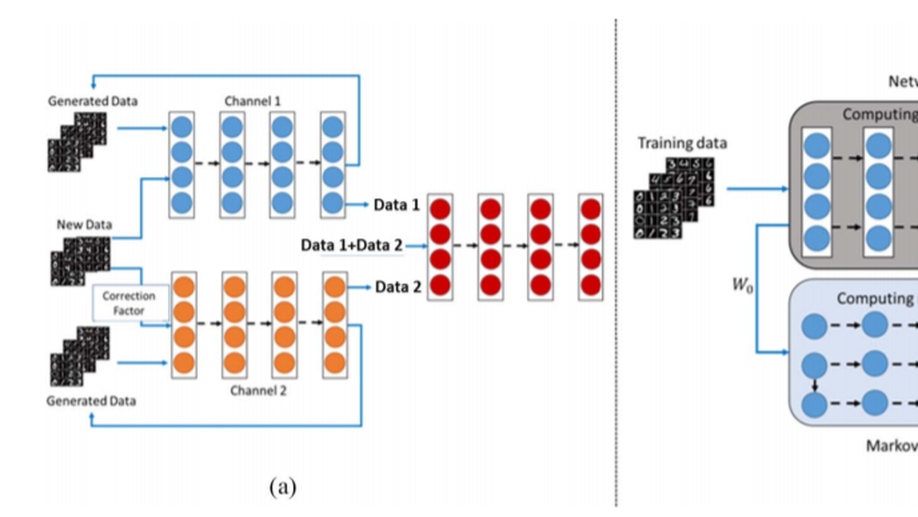
An Improved Dual-Channel Network to Eliminate Catastrophic Forgetting.
Catastrophic forgetting is a chronic problem during the online training process of deep neural networks. That is, once a new data set is used to train an existing neural network, the network will lose the ability to recognize the original data set. In literature, online contrastive divergence (CD) with generative replay (GR) exploits the generative capacity of the neural network to facilitate online training. It greatly alleviates catastrophic forgetting but cannot totally eliminate it. To overcome this shortcoming and further solve the challenging issue, in this article, we propose a novel approach named asynchronous dual-channel online restricted Boltzmann machine, where online CD with dual-channel GR plays an important role in further eliminating catastrophic forgetting. The asynchronous gradient estimation, by which the Markov chain sampling and the network calculation are conducted asynchronously on separate computing nodes, is designed to speed up training. The experimental results show that the proposed method outperforms several algorithms in increasing training speed and minimizing catastrophic forgetting. Besides, online learning with dual-channel can be effectively extended to other online learning neural networks with GR and has achieved excellent results in our verification experiments.
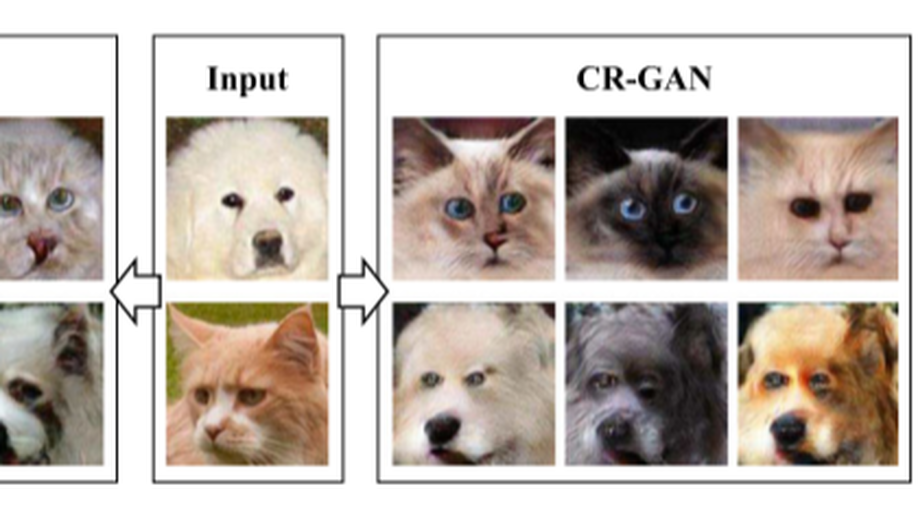
Multimodal Image-to-Image Translation between Domains with High Internal Variability.
Multimodal image-to-image translation based on generative adversarial networks (GANs) shows suboptimal performance in the visual domains with high internal variability, e.g., translation from multiple breeds of cats to multiple breeds of dogs. To alleviate this problem, we recast the training procedure as modeling distinct distributions which are observed sequentially, for example, when different classes are encountered over time. As a result, the discriminator may forget about the previous target distributions, known as catastrophic forgetting, leading to non-/slow convergence. Through experimental observation, we found that the discriminator does not always forget the previously learned distributions during training. Therefore, we propose a novel generator regulating GAN (GR-GAN). The proposed method encourages the discriminator to teach the generator more effectively when it remembers more of the previously learned distributions, while discouraging the discriminator to guide the generator when catastrophic forgetting happens on the discriminator. Both qualitative and quantitative results show that the proposed method is significantly superior to the state-of-the-art methods in handling the image data that are with high variability.
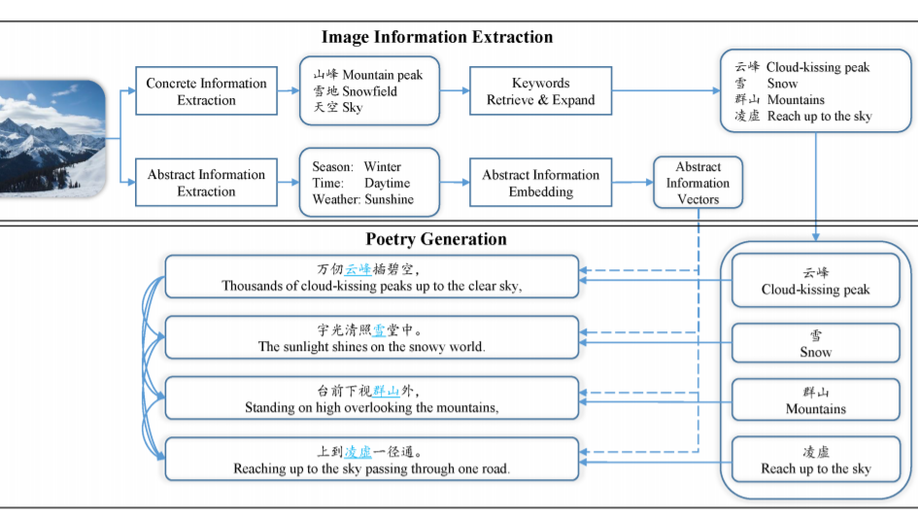
Generating Chinese Poetry from Images via Concrete and Abstract Information.
In recent years, the automatic generation of classical Chinese poetry has made great progress. Besides focusing on improving the quality of the generated poetry, there is a new topic about generating poetry from an image. However, the existing methods for this topic still have the problem of topic drift and semantic inconsistency, and the image-poem pairs dataset is hard to be built when training these models. In this paper, we extract and integrate the Concrete and Abstract information from images to address those issues. We proposed an infilling-based Chinese poetry generation model which can infill the Concrete keywords into each line of poems in an explicit way, and an abstract information embedding to integrate the Abstract information into generated poems. In addition, we use non-parallel data during training and construct separate image datasets and poem datasets to train the different components in our framework. Both automatic and human evaluation results show that our approach can generate poems which have better consistency with images without losing the quality.
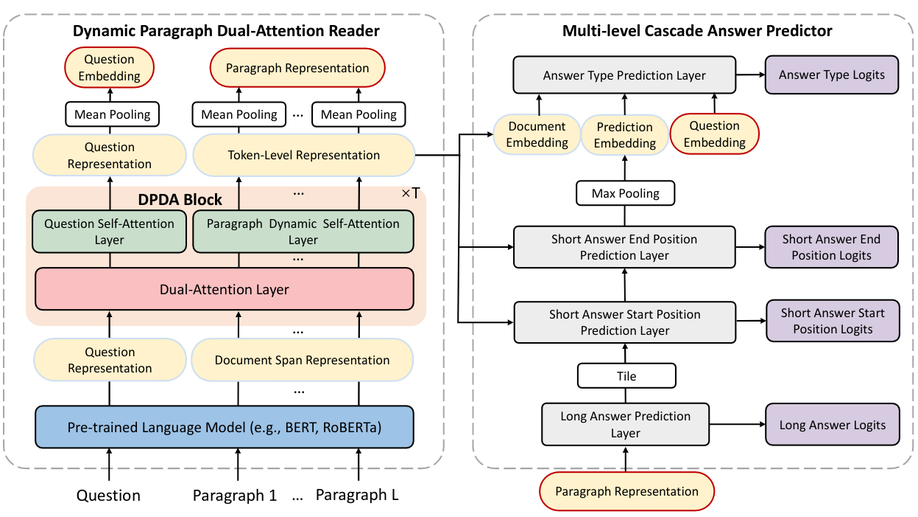
RikiNet: Reading Wikipedia Pages for Natural Question Answering.
Reading long documents to answer open-domain questions remains challenging in nat-ural language understanding. In this paper, weintroduce a new model, called RikiNet, whichreads Wikipedia pages for natural question an-swering. RikiNet contains a dynamic para-graph dual-attention reader and a multi-levelcascaded answer predictor. The reader dynam-ically represents the document and questionby utilizing a set of complementary attentionmechanisms. The representations are then fedinto the predictor to obtain the span of the shortanswer, the paragraph of the long answer, andthe answer type in a cascaded manner. Onthe Natural Questions (NQ) dataset, a singleRikiNet achieves 74.3 F1 and 57.9 F1 on long-answer and short-answer tasks. To our bestknowledge, it is the first single model that out-performs the single human performance. Fur-thermore, an ensemble RikiNet obtains 76.1F1 and 61.3 F1 on long-answer and short-answer tasks, achieving the best performanceon the official NQ leaderboard
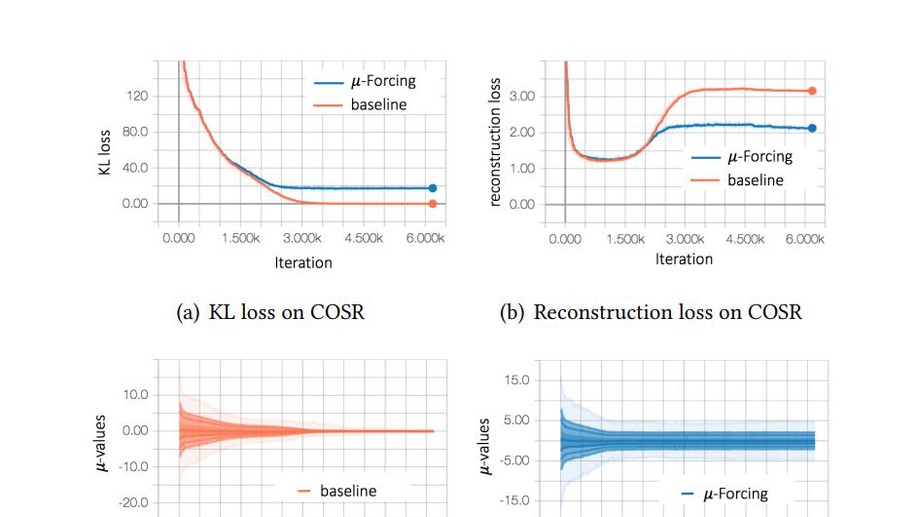
µ-Forcing:Training Variational Recurrent Autoencoders for Text Generation
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum. Sed ac faucibus dolor, scelerisque sollicitudin nisi. Cras purus urna, suscipit quis sapien eu, pulvinar tempor diam. Quisque risus orci, mollis id ante sit amet, gravida egestas nisl. Sed ac tempus magna. Proin in dui enim. Donec condimentum, sem id dapibus fringilla, tellus enim condimentum arcu, nec volutpat est felis vel metus. Vestibulum sit amet erat at nulla eleifend gravida.
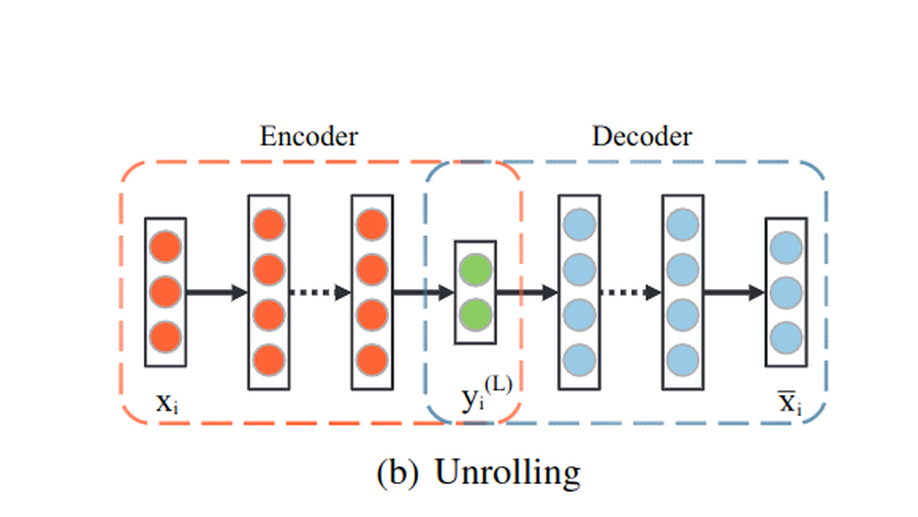
Unsupervised Multi-Manifold Clustering by Learning Deep Representation.
In this paper, we propose a novel deep manifold clustering(DMC) method for learning effective deep representationsand partitioning a dataset into clusters where each clustercontains data points from a single nonlinear manifold. Dif-ferent from other previous research efforts, we adopt deepneural network to classify and parameterize unlabeled datawhich lie on multiple manifolds. Firstly, motivated by theobservation that nearby points lie on the local of manifoldshould possess similar representations, a locality preserv-ing objective is defined to iteratively explore data relationand learn structure preserving representations. Secondly, byfinding the corresponding cluster centers from the represen-tations, a clustering-oriented objective is then proposed toguide the model to extract both discriminative and cluster-specific representations. Finally, by integrating two objectivesinto a single model with a unified cost function and opti-mizing it by using back propagation, we can obtain not onlymore powerful representations, but also more precise clustersof data. In addition, our model can be intuitively extendedto cluster out-of-sample datum. The experimental results andcomparisons with existing state-of-the-art methods show thatthe proposed method consistently achieves the best perfor-mance on various benchmark datasets
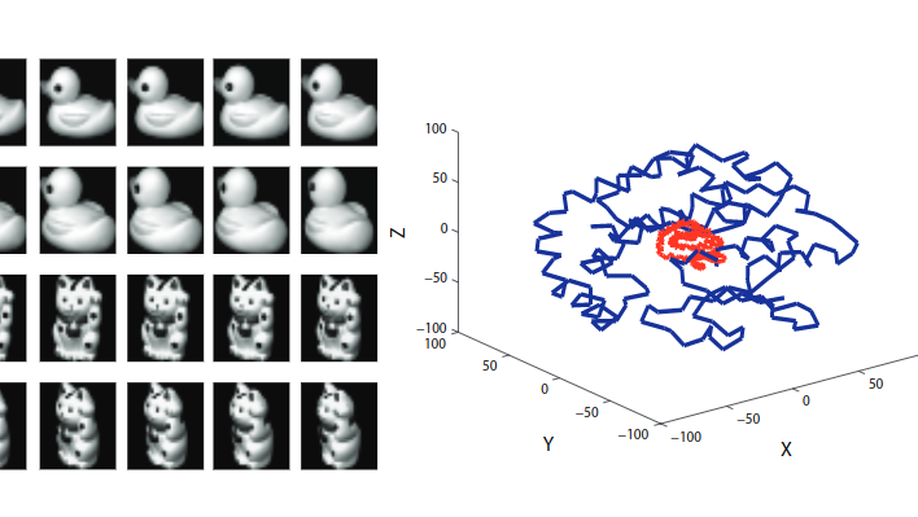
Manifold Alignment Based on Sparse LocalStructures of More Corresponding Pairs.
Manifold alignment is to extract the shared latentsemantic structure from multiple manifolds. Thejoint adjacency matrix plays a key role in mani-fold alignment. To construct the matrix, it is cru-cial to get more corresponding pairs.This pa-per proposes an approach to obtain more and re-liable corresponding pairs in terms of local struc-ture correspondence.The sparse reconstructionweight matrix of each manifold is established topreserve the local geometry of the original dataset. The sparse correspondence matrices are con-structed using the sparse local structures of corre-sponding pairs across manifolds. Further more, anew energy function for manifold alignment is pro-posed to simultaneously match the correspondinginstances and preserve the local geometry of eachmanifold. The shared low dimensional embedding,which provides better descriptions for the intrin-sic geometry and relations between different man-ifolds, can be obtained by solving the optimizationproblem with closed-form solution. Experimentsdemonstrate the effectiveness of the proposed algo-rithm.
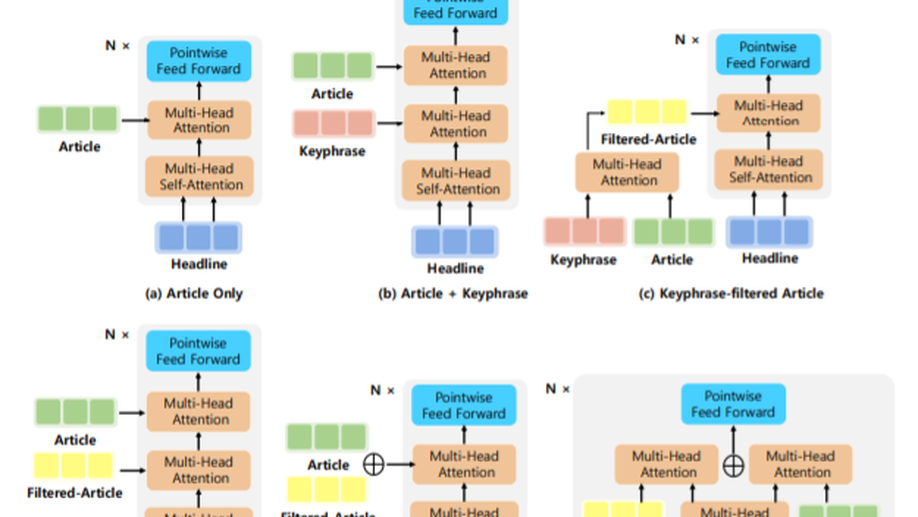
Diverse, Controllable, and Keyphrase-Aware: A Corpus and Method for News Multi-Headline Generation.
News headline generation aims to produce a short sentence to attract readers to read the news. One news article often contains multiple keyphrases that are of interest to different users, which can naturally have multiple reasonable headlines. However, most existing methods focus on the single headline generation. In this paper, we propose generating multiple headlines with keyphrases of user interests, whose main idea is to generate multiple keyphrases of interest to users for the news first, and then generate multiple keyphrase-relevant headlines. We propose a multi-source Transformer decoder, which takes three sources as inputs: (a) keyphrase, (b) keyphrase-filtered article, and (c) original article to generate keyphrase-relevant, high-quality, and diverse headlines. Furthermore, we propose a simple and effective method to mine the keyphrases of interest in the news article and build a first large-scale keyphrase-aware news headline corpus, which contains over 180K aligned triples of <news article, headline, keyphrase>. Extensive experimental comparisons on the real-world dataset show that the proposed method achieves state-of-the-art results in terms of quality and diversity.
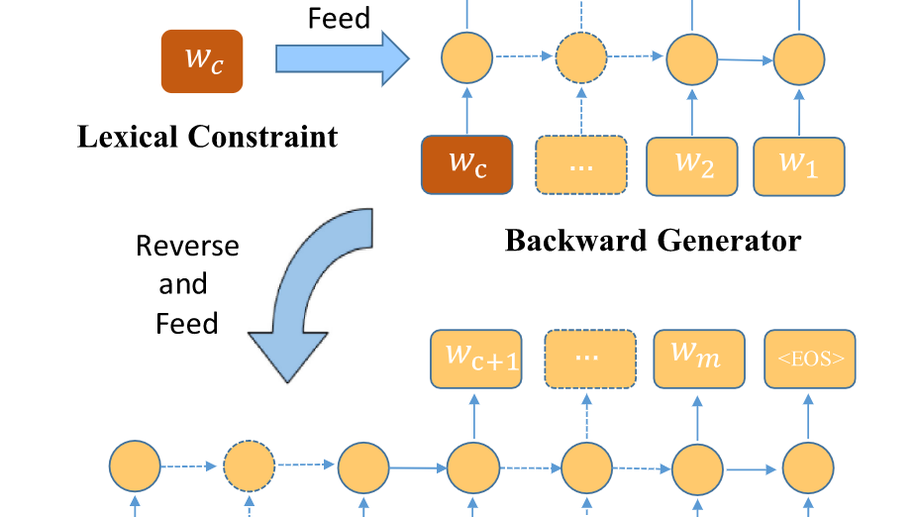
BFGAN: Backward and Forward Generative Adversarial Networks for Lexically Constrained Sentence Generation
Incorporating prior knowledge like lexical constraints into the model’s output to generate meaningful and coherent sentences has many applications in dialogue system, machine translation, image captioning, etc. However, existing auto-regressive models incrementally generate sentences from left to right via beam search, which makes it difficult to directly introduce lexical constraints into the generated sentences. In this paper, we propose a new algorithmic framework, dubbed BFGAN, to address this challenge. Specifically, we employ a backward generator and a forward generator to generate lexically constrained sentences together, and use a discriminator to guide the joint training of two generators by assigning them reward signals. Due to the difficulty of BFGAN training, we propose several training techniques to make the training process more stable and efficient. Our extensive experiments on three large-scale datasets with human evaluation demonstrate that BFGAN has significant improvements over previous methods.
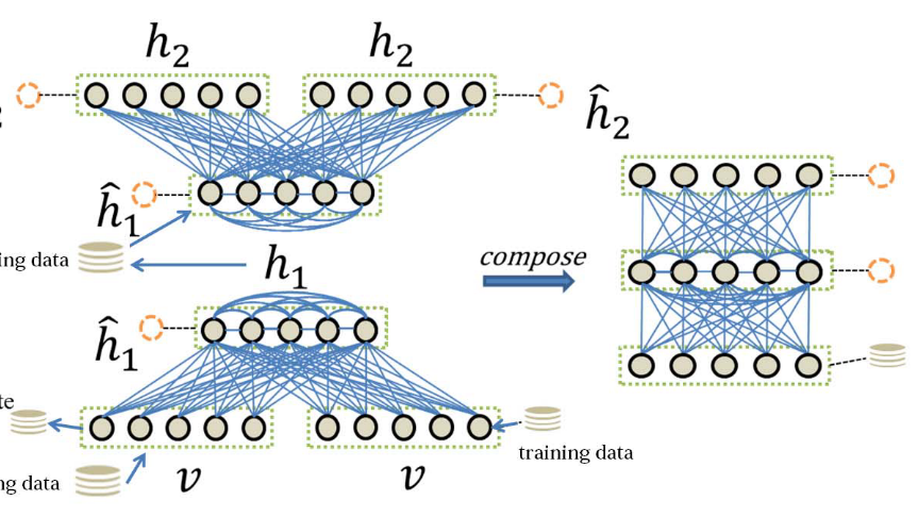
A Network Framework For Small-Sample Learning.
Small-sample learning involves training a neural network on a small-sample data set. An expansion of the training set is a common way to improve the performance of neural networks in small-sample learning tasks. However, improper constraints in expanding training data will reduce the performance of the neural networks. In this article, we present certain conditions for incorporation of additional training data. According to these conditions, we propose a neural network framework for self-training using self-generated data called small-sample learning network (SSLN). The SSLN consists of two parts: the expression learning network and the sample recall generative network, both of which are constructed based on restricted Boltzmann machine (RBM). We show that this SSLN can converge as well as the RBM. Moreover, the experiment results on MNIST Digit, SVHN, CIFAR10, and STL-10 data sets reveal the superiority of the SSLN over other models.
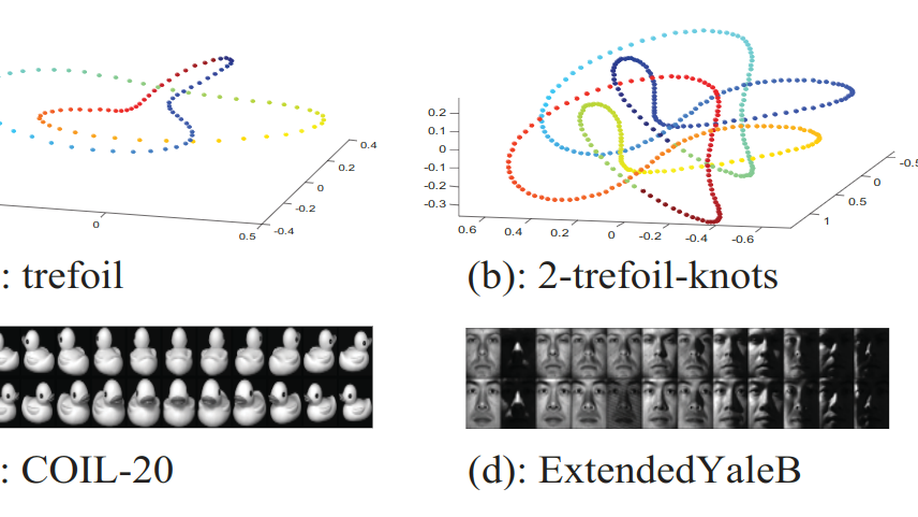
A local non-negative pursuit method for intrinsic manifold structure preservation.
The local neighborhood selection plays a crucial role for most representation based manifold learning algorithms. This paper reveals that an improper selection of neighborhood for learning representation will introduce negative components in the learnt representations. Importantly, the representations with negative components will affect the intrinsic manifold structure preservation. In this paper, a local non-negative pursuit (LNP) method is proposed for neighborhood selection and non-negative representations are learnt. Moreover, it is proved that the learnt representations are sparse and convex. Theoretical analysis and experimental results show that the proposed method achieves or outperforms the state-of-the-art results on various manifold learning problems
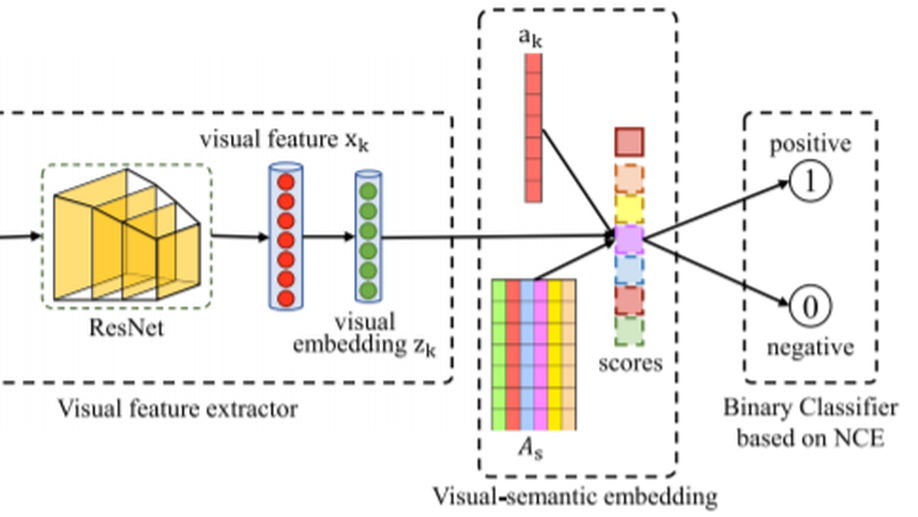
Zero-Shot Learning by Mutual Information Estimation and Maximization.
The key of zero-shot learning is to use the visual-semantic embedding to transfer the knowledge from seen classes to unseen classes. In this paper, we propose to build the visual-semantic embedding by maximizing the mutual information between visual features and corresponding attributes. Then, the mutual information between visual and semantic features can be utilized to guide the knowledge transfer from seen domain to unseen domain. Since we are primarily interested in maximizing mutual information, we introduce the noise-contrastive estimation to calculate lower-bound value of mutual information. Through the noise-contrastive estimation, we reformulate zero-shot learning as a binary classification problem, i.e., classifying the matching visual-semantic pairs (positive samples) and mismatching visual-semantic pairs (negative/noise samples). Experiments conducted on five datasets demonstrate that the proposed mutual information estimators outperforms current state-of-the-art methods both in conventional and generalized zero-shot learning settings.
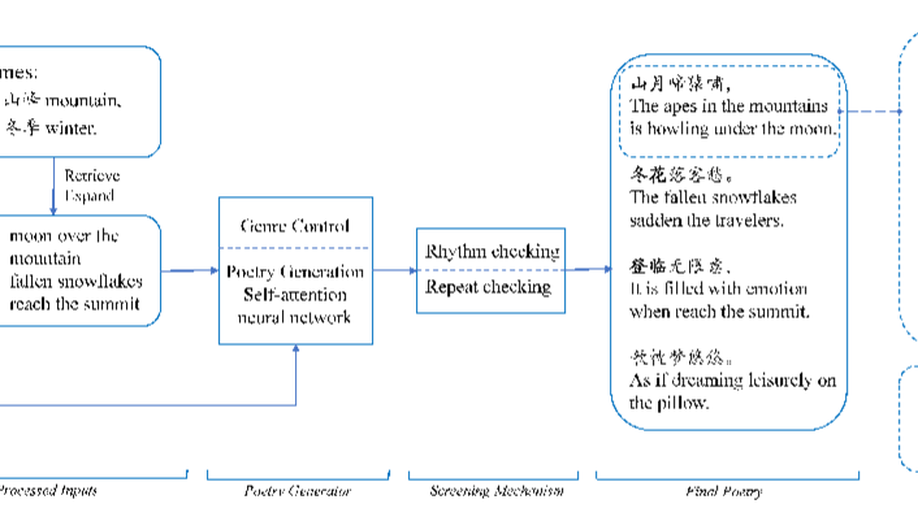
Deep Poetry: A Chinese Classical Poetry Generation System.
In this work, we demonstrate a Chinese classical poetry generation system called Deep Poetry. Existing systems for Chinese classical poetry generation are mostly template-based and very few of them can accept multi-modal input. Unlike previous systems, Deep Poetry uses neural networks that are trained on over 200 thousand poems and 3 million ancient Chinese prose. Our system can accept plain text, images or artistic conceptions as inputs to generate Chinese classical poetry. More importantly, users are allowed to participate in the process of writing poetry by our system. For the user’s convenience, we deploy the system at the WeChat applet platform, users can use the system on the mobile device whenever and wherever possible.
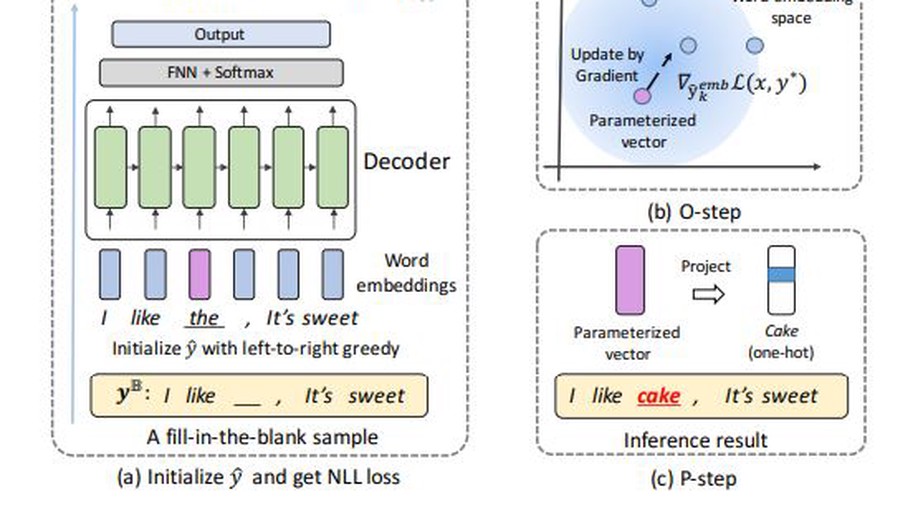
An Inference Algorithm for Text Infilling with Gradient Search
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum. Sed ac faucibus dolor, scelerisque sollicitudin nisi. Cras purus urna, suscipit quis sapien eu, pulvinar tempor diam. Quisque risus orci, mollis id ante sit amet, gravida egestas nisl. Sed ac tempus magna. Proin in dui enim. Donec condimentum, sem id dapibus fringilla, tellus enim condimentum arcu, nec volutpat est felis vel metus. Vestibulum sit amet erat at nulla eleifend gravida.
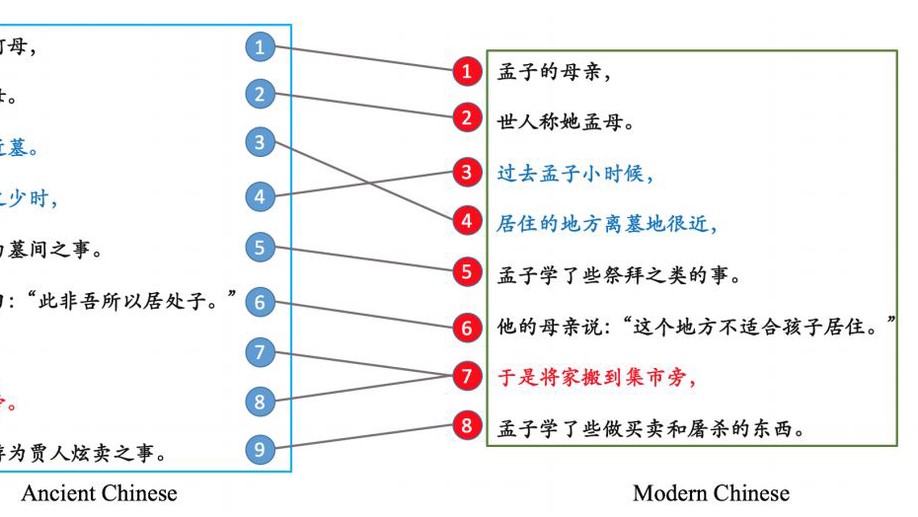
Ancient-Modern Chinese Translation with a New Large Training Dataset
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis posuere tellus ac convallis placerat. Proin tincidunt magna sed ex sollicitudin condimentum. Sed ac faucibus dolor, scelerisque sollicitudin nisi. Cras purus urna, suscipit quis sapien eu, pulvinar tempor diam. Quisque risus orci, mollis id ante sit amet, gravida egestas nisl. Sed ac tempus magna. Proin in dui enim. Donec condimentum, sem id dapibus fringilla, tellus enim condimentum arcu, nec volutpat est felis vel metus. Vestibulum sit amet erat at nulla eleifend gravida.

















